- Un namespace Linux e' una zona di rete isolata: ha le sue interfacce, le sue rotte, il suo stack IP
- I veth pair sono i cavi virtuali che collegano i namespace - equivalenti dei cavi fisici in Cisco
iptables -P FORWARD DROPe' il security-level dell'ASA: blocca tutto il traffico in transito per default- Le ACL diventano
iptables -A FORWARD: stessa logica, sintassi diversa
▶ $ history
ip netns add- crea un namespaceip link add veth0 type veth peer name veth1- crea un cavo virtualeip netns exec <ns> <comando>- esegue un comando dentro un namespaceiptables -P FORWARD DROP- blocca tutto il traffico in transitoiptables -A FORWARD- aggiunge una regola di permesso
Perche' questo lab#
Stesso scenario del cisco-packet-tracer-dmz|lab Cisco: corsobitcoin.com con Sofia/nginx nella DMZ e Giulia/MySQL nella LAN privata.
La differenza: nessun ASA, nessuno switch fisico, nessun Packet Tracer. Solo una VM Ubuntu e i comandi giusti.
In Cisco il firewall e' un dispositivo dedicato con security-level e nameif. In Linux e' un namespace con iptables. In Cisco le VLAN separano i segmenti a livello 2. In Linux la separazione e' gia' nella struttura dei namespace - ogni veth pair e' un segmento isolato.
Stesso risultato, strumenti diversi.
mindmap
root((Perche questo lab))
Scenario
corsobitcoin.com
Sofia nginx in DMZ
Giulia MySQL in LAN
Confronto Cisco vs Linux
ASA sostituito da iptables
Switch sostituito da veth pair
VLAN sostituite da namespace
Obiettivo
Stessa topologia
Zero hardware dedicato
Solo Ubuntu e comandi
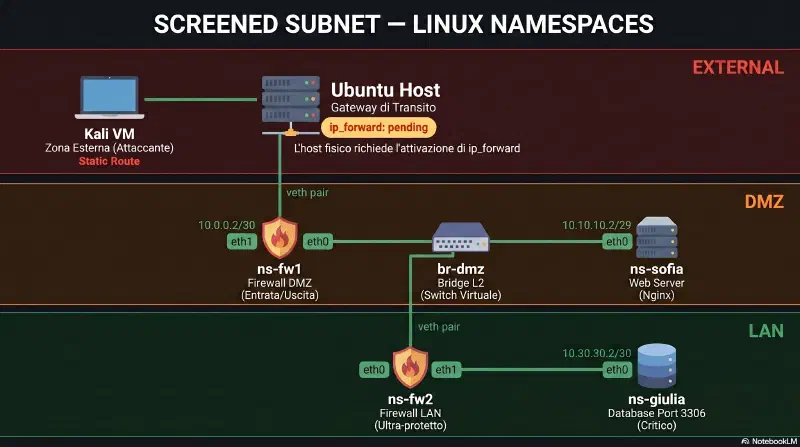
La topologia#
La topologia logica e' identica al cisco-packet-tracer-dmz|lab Cisco. In Linux i namespace sostituiscono i dispositivi fisici, i veth pair sostituiscono i cavi e gli switch, iptables sostituisce il security-level ASA.
A differenza del lab Cisco dove Kali era un PC simulato, qui Kali e' una VM reale (192.168.64.200) che attacca dall'esterno. Tutti i namespace girano su Ubuntu (192.168.64.3). ns-kali non esiste - Kali e' gia' fuori.
graph TD
KALI["Kali VM
192.168.64.200"]
UBUNTU["Ubuntu host
192.168.64.3
enp0s1 → rete UTM"]
FW1["ns-fw1
iptables — FW1
out: 10.0.0.2/30
dmz: 10.10.10.1/29"]
BRDMZ["br-dmz
switch virtuale L2"]
SOFIA["ns-sofia
nginx + WAF
10.10.10.2/29"]
FW2["ns-fw2
iptables — FW2
dmz: 10.10.10.3/29
lan: 10.30.30.1/30"]
GIULIA[("ns-giulia
netcat 3306
10.30.30.2/30")]
KALI -- "UTM host-only" --> UBUNTU
UBUNTU -- "veth-host 10.0.0.1/30" --> FW1
FW1 -- "veth-fw1-dmz" --> BRDMZ
BRDMZ -- "veth-sofia" --> SOFIA
BRDMZ -- "veth-fw2-dmz" --> FW2
FW2 -- "veth-fw2-lan / veth-giulia" --> GIULIA
classDef external fill:#2d1515,stroke:#e05555,color:#fff
classDef dmz fill:#2d1a0d,stroke:#ff7a4a,color:#fff
classDef lan fill:#0d2318,stroke:#4aaf7e,color:#fff
classDef fw fill:#0d1a2d,stroke:#4a9eff,color:#fff
class KALI,UBUNTU external
class SOFIA,BRDMZ dmz
class GIULIA lan
class FW1,FW2 fw
flowchart LR
classDef ext fill:#4a0d0d,stroke:#e05555,color:#eee
classDef fw fill:#0d1a3d,stroke:#4a9eff,color:#eee
classDef dmz fill:#3d2a0d,stroke:#ffaa4a,color:#eee
classDef lan fill:#0d2d15,stroke:#4aff7e,color:#eee
subgraph EXT[Zona esterna]
KALI(["🌐 Kali
192.168.64.200"]):::ext
FW1(["🛡 ns-fw1
iptables FW1"]):::fw
end
subgraph DMZ[DMZ 10.10.10.0/29]
SOFIA(["🖥 ns-sofia
nginx + WAF"]):::dmz
FW2(["🛡 ns-fw2
iptables FW2"]):::fw
end
subgraph LAN[LAN 10.30.30.0/30]
GIULIA[("🗄 ns-giulia
MySQL")]:::lan
end
KALI --> FW1
FW1 --> SOFIA
FW1 --> FW2
FW2 --> GIULIA
Per far raggiungere a Kali la rete 10.0.0.0/30 di ns-fw1, aggiungiamo una rotta su Kali:
# su Kali VM - dice a Kali che per raggiungere 10.0.0.0/30
# deve passare per Ubuntu (192.168.64.3)
sudo ip route add 10.0.0.0/30 via 192.168.64.3| Cisco | Linux | Ruolo |
|---|---|---|
| PC-Kali | Kali VM 192.168.64.200 | attaccante reale, fuori da Ubuntu |
| SW-EXT | veth pair | cavo virtuale (no namespace) |
| FW1 ASA | ns-fw1 + iptables | firewall perimetrale |
| SW-DMZ | veth pair | cavo virtuale |
| Sofia/nginx | ns-sofia + nginx | web server / WAF in DMZ |
| FW2 ASA | ns-fw2 + iptables | firewall interno |
| SW-LAN | veth pair | cavo virtuale |
| Giulia/MySQL | ns-giulia + netcat | database in LAN |
Gli switch non diventano namespace - sono solo veth pair. Un veth pair e' un cavo virtuale: due interfacce collegate, quello che entra da una esce dall'altra.
Riferimento rapido#
ns-fw1
veth-fw1-out 10.0.0.2/30 -> host (Kali arriva da qui)
veth-fw1-dmz 10.10.10.1/29 -> br-dmz (switch virtuale L2)
br-dmz <- bridge Linux = SW-DMZ del lab Cisco. Commuta frame L2 tra FW1, Sofia e FW2
veth-fw1-dmz-br -> ns-fw1
veth-sofia-br -> ns-sofia
veth-fw2-dmz-br -> ns-fw2
ns-fw2
veth-fw2-dmz 10.10.10.3/29 -> br-dmz (switch virtuale L2)
veth-fw2-lan 10.30.30.1/30 -> ns-giulia
HOSTS
Kali VM 10.0.0.1/30 gw: 10.0.0.2 (rotta aggiunta su Kali)
ns-sofia 10.10.10.2/29 gw: 10.10.10.1
ns-giulia 10.30.30.2/30 gw: 10.30.30.1
ROTTE
ns-fw1: ip route add default via 10.0.0.1
ns-fw1: ip route add 10.30.30.0/30 via 10.10.10.3
ns-fw2: ip route add default via 10.10.10.1mindmap
root((Riferimento rapido))
ns-fw1
veth-fw1-out 10.0.0.2/30
veth-fw1-dmz 10.10.10.1/29
br-dmz
veth-fw1-dmz-br
veth-sofia-br
veth-fw2-dmz-br
ns-fw2
veth-fw2-dmz 10.10.10.3/29
veth-fw2-lan 10.30.30.1/30
Hosts
Kali 10.0.0.1/30
ns-sofia 10.10.10.2/29
ns-giulia 10.30.30.2/30
Rotte statiche
ns-fw1 default via 10.0.0.1
ns-fw1 LAN via 10.10.10.3
ns-fw2 default via 10.10.10.1
Schema IP#
| Zona | Subnet | Namespace | IP |
|---|---|---|---|
| Esterna | 10.0.0.0/30 | ns-kali | 10.0.0.1 |
| Esterna | 10.0.0.0/30 | ns-fw1 (out) | 10.0.0.2 |
| DMZ | 10.10.10.0/29 | ns-fw1 (dmz) | 10.10.10.1 |
| DMZ | 10.10.10.0/29 | ns-sofia | 10.10.10.2 |
| DMZ | 10.10.10.0/29 | ns-fw2 (dmz) | 10.10.10.3 |
| LAN | 10.30.30.0/30 | ns-fw2 (lan) | 10.30.30.1 |
| LAN | 10.30.30.0/30 | ns-giulia | 10.30.30.2 |
Gli IP sono identici al lab Cisco. Stessa topologia, stessi indirizzi, strumenti diversi.
mindmap
root((Schema IP))
Zona esterna
10.0.0.0/30
ns-kali 10.0.0.1
ns-fw1 out 10.0.0.2
DMZ
10.10.10.0/29
ns-fw1 dmz 10.10.10.1
ns-sofia 10.10.10.2
ns-fw2 dmz 10.10.10.3
LAN
10.30.30.0/30
ns-fw2 lan 10.30.30.1
ns-giulia 10.30.30.2
VLAN in Linux: non esistono, e non servono#
Nel cisco-packet-tracer-dmz|lab Cisco abbiamo configurato VLAN 10, 20 e 30 su tre switch separati. Qui non c'e' nessuna VLAN da configurare - e l'isolamento funziona lo stesso.
In Cisco le VLAN erano necessarie perche' tutto passava per switch fisici condivisi. Senza VLAN, Kali e Sofia si vedevano a livello 2 sullo stesso switch. Le VLAN mettevano muri tra le zone.
In Linux ogni veth pair e' un cavo punto-punto dedicato. ns-sofia non ha nessuna interfaccia verso Kali - fisicamente il collegamento non esiste. Non c'e' nessuno switch condiviso dove i frame si potrebbero mescolare.
flowchart LR
classDef ext fill:#4a0d0d,stroke:#e05555,color:#eee
classDef fw fill:#0d1a3d,stroke:#4a9eff,color:#eee
classDef dmz fill:#3d2a0d,stroke:#ffaa4a,color:#eee
classDef lan fill:#0d2d15,stroke:#4aff7e,color:#eee
KALI["Kali VM"]:::ext
FW1["ns-fw1"]:::fw
SOFIA["ns-sofia"]:::dmz
FW2["ns-fw2"]:::fw
GIULIA[("ns-giulia")]:::lan
KALI <-->|"veth pair"| FW1
FW1 <-->|"veth pair"| SOFIA
SOFIA <-->|"veth pair"| FW2
FW2 <-->|"veth pair"| GIULIA
| Cisco | Linux namespace |
|---|---|
| SW-EXT + VLAN 10 | veth tra host e ns-fw1 |
| SW-DMZ + VLAN 20 | veth tra ns-fw1 e ns-sofia + veth tra ns-sofia e ns-fw2 |
| SW-LAN + VLAN 30 | veth tra ns-fw2 e ns-giulia |
L'isolamento che in Cisco richiedeva switch + configurazione VLAN, in Linux e' gia' nella struttura dei namespace. Non puoi sbagliare VLAN perche' le VLAN non esistono.
Le VLAN nella realta'#
Le VLAN in produzione si configurano quando hai un'infrastruttura fisica condivisa - switch reali con tanti dispositivi collegati sullo stesso hardware:
Switch fisico in datacenter
├── porta 1 → server web 1 VLAN 10 (DMZ)
├── porta 2 → server web 2 VLAN 10 (DMZ)
├── porta 3 → database 1 VLAN 20 (LAN)
├── porta 4 → database 2 VLAN 20 (LAN)
├── porta 5 → FW1 VLAN 10 (DMZ)
└── porta 6 → FW2 VLAN 20 (LAN)Tutti fisicamente sullo stesso switch. Senza VLAN si vedrebbero tutti a livello 2. Le VLAN creano la separazione.
Ogni ambiente risolve lo stesso problema con strumenti diversi:
| Ambiente | Strumento di isolamento |
|---|---|
| Cisco / switch fisico | VLAN su porte dello switch |
| Linux namespaces | isolamento implicito nei veth pair |
| Docker | docker network |
| AWS / Azure | subnet + security group |
In cloud le VLAN non esistono come concetto - esistono le subnet dentro una VPC (Virtual Private Cloud) e i security group che decidono chi puo' parlare con chi. E' esattamente lo stesso modello: zona esterna, DMZ, LAN privata - ma tutto software, gestito dal provider. Quello che in Cisco richiedeva switch fisici e cavi, in AWS si configura sulla console. Il concetto sotto e' identico: isola le zone, controlla il traffico tra di esse.
mindmap
root((VLAN nella realta))
Switch fisico in datacenter
Porta server web VLAN 10 DMZ
Porta database VLAN 20 LAN
Porte FW collegate a entrambe
Equivalenti software
Linux namespaces veth pair
Docker docker network
AWS subnet e security group
Concetto comune
Zona esterna
DMZ
LAN privata
Creazione namespace#
Nel cisco-packet-tracer-dmz|lab Cisco questa era la fase in cui trascinavo i dispositivi sulla canvas: FW1, FW2, SW-DMZ, i PC. In Linux non c'e' canvas - i dispositivi si creano da terminale.
Un network namespace e' uno stack IP completamente isolato: interfacce proprie, routing table propria, regole iptables proprie. Stesso kernel, rete separata. Quattro namespace = quattro "router virtuali" indipendenti sullo stesso Ubuntu.
ip netns exec ns-fw1 <comando> funziona come docker exec <container> <comando>: entra nel contesto di rete di quel namespace ed esegue. La differenza e' che un namespace isola solo la rete - Docker isola anche filesystem, processi e utenti usando piu' tipi di namespace insieme. Ogni container Docker ha dentro di se' un network namespace - e' lo stesso meccanismo sotto il cofano.
ip netns list
# ns-giulia (id: 6)
# ns-fw2 (id: 5)
# ns-sofia (id: 4)
# ns-fw1 (id: 3)Gli ID sono assegnati dal kernel nell'ordine di creazione - ns-fw1 per primo (id 3), ns-giulia per ultimo (id 6). Sono identificatori interni, non ci servono per niente.
# crea ns-fw1 - equivalente di FW1 ASA in Cisco.
# sara' il firewall perimetrale tra Kali e la DMZ.
# ci metteremo iptables con policy DROP, come il security-level 0/50 dell'ASA
sudo ip netns add ns-fw1
# crea ns-sofia - equivalente di Sofia/nginx in Cisco.
# la zona di mezzo: esposta verso Kali, separata dalla LAN.
# ci installeremo nginx + ModSecurity come WAF reale
sudo ip netns add ns-sofia
# crea ns-fw2 - equivalente di FW2 ASA in Cisco.
# il secondo firewall: protegge ns-giulia dalla DMZ.
# stessa logica di FW2: security-level 50 verso dmz, 100 verso inside
sudo ip netns add ns-fw2
# crea ns-giulia - equivalente di Giulia/MySQL in Cisco.
# la zona piu' protetta: raggiungibile solo attraverso ns-fw2.
# useremo netcat sulla porta 3306 per simulare MySQL
sudo ip netns add ns-giulia
# verifica: mostra tutti i namespace creati
# equivalente di guardare la canvas in Packet Tracer e vedere i dispositivi
ip netns listOutput atteso:
ns-giulia
ns-fw2
ns-sofia
ns-fw1Quattro namespace, quattro zone. Ogni namespace corrisponde a un attore del lab Cisco:
| Cisco | Linux | Note |
|---|---|---|
| FW1 ASA | ns-fw1 | firewall perimetrale |
| Sofia/nginx | ns-sofia | web server in DMZ |
| FW2 ASA | ns-fw2 | firewall interno |
| Giulia/MySQL | ns-giulia | database in LAN |
| PC-Kali | Kali VM reale | fuori da Ubuntu, nessun namespace |
| SW-EXT / SW-DMZ / SW-LAN | veth pair / br-dmz | cavi virtuali, non hanno stack IP |
Gli switch non diventano namespace perche' non hanno bisogno di un routing table o di iptables - sono solo cavi. I namespace sono per i dispositivi che elaborano pacchetti.
A questo punto i namespace esistono ma sono vuoti: nessuna interfaccia, nessun IP, nessuna rotta. E' come aver posizionato i dispositivi sulla canvas di Packet Tracer ma senza ancora collegare i cavi o configurare gli IP.
mindmap
root((Creazione namespace))
Concetto
Stack IP isolato
Interfacce proprie
Routing table propria
iptables proprie
Namespace del lab
ns-fw1 firewall perimetrale
ns-sofia web server DMZ
ns-fw2 firewall interno
ns-giulia database LAN
Comandi
ip netns add
ip netns list
ip netns exec
Analogia
Cisco canvas con dispositivi
Docker exec stesso meccanismo
Solo rete isolata non filesystem
Veth pair - i cavi virtuali#
Nel cisco-packet-tracer-dmz|lab Cisco questa era la fase in cui trascinavo i cavi tra i dispositivi sulla canvas. In Linux i cavi si chiamano veth pair: due interfacce virtuali collegate tra loro - quello che entra da una esce dall'altra.
Una differenza importante rispetto a Cisco: nel lab Cisco la DMZ aveva tre dispositivi sullo stesso switch fisico (FW1, Sofia, FW2) tutti sulla subnet 10.10.10.0/29. Per replicarlo fedelmente usiamo un bridge Linux - uno switch virtuale che collega tutti e tre nella stessa zona L2. Senza bridge, FW1 e FW2 non si vedrebbero a livello 2 e non potrebbero condividere la stessa subnet.
# --- link esterno: host <-> ns-fw1 ---
# equivalente del cavo tra SW-EXT e FW1 in Cisco.
# "veth-host" resta nel namespace host (Ubuntu), "veth-fw1-out" va dentro ns-fw1.
# Kali VM raggiungera' ns-fw1 attraverso Ubuntu - per questo serve una rotta su Kali
sudo ip link add veth-host type veth peer name veth-fw1-out
# sposta veth-fw1-out dentro ns-fw1 - da questo momento quella interfaccia
# appartiene esclusivamente a ns-fw1 e non e' piu' visibile dal host
sudo ip link set veth-fw1-out netns ns-fw1
# --- bridge DMZ (br = bridge): equivalente di SW-DMZ con VLAN 20 ---
# un bridge Linux e' uno switch virtuale L2 - commuta frame in base al MAC,
# non instrada pacchetti IP. "br-dmz" e' SW-DMZ del lab Cisco.
# senza bridge, ns-fw1 e ns-fw2 sarebbero su link punto-punto separati
# e non potrebbero condividere la stessa subnet 10.10.10.0/29
sudo ip link add br-dmz type bridge
# attiva il bridge - senza questo e' creato ma non processa traffico
sudo ip link set br-dmz up
# veth pair per collegare ns-fw1 al bridge DMZ.
# "veth-fw1-dmz" va dentro ns-fw1, "veth-fw1-dmz-br" resta nel host collegato al bridge.
# equivalente del cavo tra FW1 Gig1/2 (dmz) e SW-DMZ
sudo ip link add veth-fw1-dmz type veth peer name veth-fw1-dmz-br
sudo ip link set veth-fw1-dmz netns ns-fw1
sudo ip link set veth-fw1-dmz-br master br-dmz
sudo ip link set veth-fw1-dmz-br up
# veth pair per collegare ns-sofia al bridge DMZ.
# "veth-sofia" va dentro ns-sofia, "veth-sofia-br" resta nel host collegato al bridge.
# equivalente del cavo tra Sofia/nginx e SW-DMZ
sudo ip link add veth-sofia type veth peer name veth-sofia-br
sudo ip link set veth-sofia netns ns-sofia
sudo ip link set veth-sofia-br master br-dmz
sudo ip link set veth-sofia-br up
# veth pair per collegare ns-fw2 al bridge DMZ.
# "veth-fw2-dmz" va dentro ns-fw2, "veth-fw2-dmz-br" resta nel host collegato al bridge.
# equivalente del cavo tra FW2 Gig1/1 (dmz) e SW-DMZ
sudo ip link add veth-fw2-dmz type veth peer name veth-fw2-dmz-br
sudo ip link set veth-fw2-dmz netns ns-fw2
sudo ip link set veth-fw2-dmz-br master br-dmz
sudo ip link set veth-fw2-dmz-br up
# --- link LAN: ns-fw2 <-> ns-giulia ---
# equivalente del cavo tra SW-LAN e FW2 Gig1/2 (inside) / Giulia/MySQL.
# solo due dispositivi - non serve bridge, basta un veth pair diretto
sudo ip link add veth-fw2-lan type veth peer name veth-giulia
sudo ip link set veth-fw2-lan netns ns-fw2
sudo ip link set veth-giulia netns ns-giuliaA questo punto i cavi esistono ma le interfacce sono ancora spente e senza IP. E' come aver collegato i cavi in Packet Tracer ma non aver ancora configurato gli IP sulle interfacce - le linee sono verdi ma non passa niente.
Per verificare cosa e' stato creato nel host namespace:
ip link show | grep veth# le prime 3 righe (veth012dcee, veth2f919ce, veth85d8349) sono di Wazuh - gia' presenti, ignorate
6: veth012dcee@if2: ... master wazuh-br0 state UP <- Wazuh, non toccare
7: veth2f919ce@if2: ... master wazuh-br0 state UP <- Wazuh, non toccare
8: veth85d8349@if2: ... master wazuh-br0 state UP <- Wazuh, non toccare
# queste sono le nostre:
10: veth-host@if9: state DOWN <- lato host del link verso ns-fw1 (outside)
12: veth-fw1-dmz-br@if13: master br-dmz state DOWN <- ns-fw1 collegato al bridge DMZ
14: veth-sofia-br@if14: master br-dmz state LOWERLAYERDOWN <- ns-sofia collegata al bridge DMZ
16: veth-fw2-dmz-br@if17: master br-dmz state LOWERLAYERDOWN <- ns-fw2 collegata al bridge DMZ
19: veth-fw2-lan@if18: state DOWN <- lato host del link verso ns-giuliaLOWERLAYERDOWN significa che l'altra meta' del veth pair (quella dentro il namespace) e' ancora spenta. Normale - non abbiamo ancora fatto ip link set up sulle interfacce interne.
Dentro ogni namespace:
sudo ip netns exec ns-fw1 ip link show
sudo ip netns exec ns-sofia ip link show
sudo ip netns exec ns-fw2 ip link show
sudo ip netns exec ns-giulia ip link show# ns-fw1: due interfacce, entrambe DOWN
9: veth-fw1-out@if10 state DOWN <- verso host (Kali arrivera' da qui)
13: veth-fw1-dmz@if12 state DOWN <- verso bridge DMZ (Sofia e FW2)
# ns-sofia: una interfaccia, DOWN
15: veth-sofia@if14 state DOWN <- verso bridge DMZ
# ns-fw2: una interfaccia, DOWN
17: veth-fw2-dmz@if16 state DOWN <- verso bridge DMZ (FW1 e Sofia)
# ns-giulia: una interfaccia, DOWN
18: veth-giulia@if19 state DOWN <- verso ns-fw2Tutti i cavi sono collegati, nessuna interfaccia e' attiva. Il prossimo passo e' assegnare gli IP e fare ip link set up su ogni interfaccia.
mindmap
root((Veth pair))
Concetto
Due interfacce virtuali collegate
Tutto in entra da una esce dallaltra
Equivalente cavo fisico Cisco
Struttura del lab
veth-host verso ns-fw1
br-dmz bridge DMZ switch virtuale L2
veth-fw1-dmz-br
veth-sofia-br
veth-fw2-dmz-br
veth-fw2-lan verso ns-giulia
Perche il bridge DMZ
Tre dispositivi sulla stessa subnet
FW1 Sofia FW2 su 10.10.10.0/29
Senza bridge non si vedono a L2
Comandi
ip link add type veth peer
ip link set netns
ip link set master br-dmz
Nota: topologia L2 vs routing#
Nel lab Cisco il segmento esterno aveva tre partecipanti sulla stessa rete L2: Kali, Mac (gateway UTM) e FW1 outside. In questo lab usiamo routing L3 attraverso Ubuntu host - piu' semplice, stessa sostanza.
Kali VM (192.168.64.200)
| ip route add 10.0.0.0/30 via 192.168.64.3
v
Ubuntu host (192.168.64.3)
enp0s1 <- interfaccia fisica verso la rete UTM host-only (192.168.64.0/24)
| ip_forward attivo: riceve su enp0s1, gira su veth-host
| veth-host 10.0.0.1/30
v
ns-fw1 veth-fw1-out 10.0.0.2/30enp0s1 e' il nome che Linux assegna alla prima interfaccia ethernet fisica di Ubuntu - in UTM su Apple Silicon corrisponde all'adattatore di rete virtuale connesso alla rete host-only 192.168.64.0/24. E' l'interfaccia su cui arrivano i pacchetti di Kali prima che ip_forward li giri verso ns-fw1.
Kali non si accorge di Ubuntu: manda il pacchetto verso 10.0.0.2 e Ubuntu lo instrada nel namespace tramite ip_forward. L'isolamento tra zone e' garantito dalla struttura dei namespace stessi - ns-sofia non ha nessuna interfaccia verso il link esterno, fisicamente il collegamento non esiste.
mindmap
root((Topologia L2 vs routing))
Cisco lab
Kali Mac FW1 stessa rete L2
Stesso switch fisico
Linux lab
Routing L3 attraverso Ubuntu host
Kali manda a Ubuntu
Ubuntu gira a ns-fw1 via ip forward
Percorso pacchetto
Kali 192.168.64.200
Ubuntu enp0s1 poi veth-host 10.0.0.1
ns-fw1 veth-fw1-out 10.0.0.2
Configurazione IP#
Per completezza: nel lab Cisco siamo all'equivalente di cisco-packet-tracer-dmz#FW1 - configurazione|FW1 - configurazione — la parte
ip address+no shutdown. Ilnameife ilsecurity-levelarrivano dopo con iptables.
In Cisco Packet Tracer a questo punto avremmo tutti i triangoli rossi: i cavi sono collegati ma le interfacce sono in shutdown. Assegnare gli IP e fare ip link set up e' l'equivalente di no shutdown + ip address su ogni interfaccia.
# --- host namespace ---
# veth-host e' il lato Ubuntu del link verso ns-fw1.
# in Cisco era il gateway UTM sulla rete esterna - non un dispositivo del lab,
# ma serve un IP per fare da nexthop quando Kali manda traffico verso 10.0.0.2
sudo ip addr add 10.0.0.1/30 dev veth-host
sudo ip link set veth-host up
# attiva il bridge DMZ - lo switch virtuale che collega FW1, Sofia e FW2
sudo ip link set br-dmz up
# --- ns-fw1 ---
# equivalente di FW1 Gig1/1 outside: ip address 10.0.0.2 255.255.255.252 + no shutdown
sudo ip netns exec ns-fw1 ip link set lo up
sudo ip netns exec ns-fw1 ip addr add 10.0.0.2/30 dev veth-fw1-out
sudo ip netns exec ns-fw1 ip link set veth-fw1-out up
# equivalente di FW1 Gig1/2 dmz: ip address 10.10.10.1 255.255.255.248 + no shutdown
sudo ip netns exec ns-fw1 ip addr add 10.10.10.1/29 dev veth-fw1-dmz
sudo ip netns exec ns-fw1 ip link set veth-fw1-dmz up
# equivalente di "route outside 0.0.0.0 0.0.0.0 10.0.0.1"
sudo ip netns exec ns-fw1 ip route add default via 10.0.0.1
# equivalente di "route dmz 10.30.30.0 255.255.255.252 10.10.10.3"
sudo ip netns exec ns-fw1 ip route add 10.30.30.0/30 via 10.10.10.3A questo punto ns-fw1 ha due interfacce su due reti diverse: 10.0.0.2/30 su veth-fw1-out (outside) e 10.10.10.1/29 su veth-fw1-dmz (dmz). Ha letteralmente "un piede" in ciascuna rete - ed e' proprio questo che lo rende un router e non un host qualunque.
Per le reti a cui e' collegato direttamente, il kernel non ha bisogno di istruzioni: appena assegni un IP a un'interfaccia, Linux aggiunge da solo una rotta "kernel" per quella subnet. Per tutto il resto, ns-fw1 guarda la sua routing table riga per riga:
default via 10.0.0.1- il gateway, il "prossimo salto" per qualsiasi destinazione che non compare in nessun'altra riga. E' la rotta verso Ubuntu/Kali, sull'interfaccia outside.10.30.30.0/30 via 10.10.10.3- ns-fw1 non ha un'interfaccia sulla LAN, ma sa che ns-fw2 (10.10.10.3, raggiungibile sullo stesso bridge DMZ) sa come arrivarci. Per quella rete specifica, il prossimo salto non e' il default gateway ma ns-fw2.
Senza questa seconda riga, un pacchetto diretto a 10.30.30.2 (ns-giulia) prenderebbe il default gateway e finirebbe verso Ubuntu/Kali invece che verso la LAN. Una rotta esplicita per la rete di destinazione vince sempre sul default: il default e' solo il "non so cosa farne, prova di la'".
Il /30 e il /29 sono la subnet mask in notazione CIDR: dicono quanti indirizzi appartengono a quella rete. /30 = 4 indirizzi (2 usabili, il link outside tra ns-fw1 e Ubuntu), /29 = 8 indirizzi (6 usabili, la DMZ condivisa da FW1, Sofia e FW2). Il router non deve conoscere ogni singolo host della rete: sa che tutto cio' che rientra in quel range e' raggiungibile su quell'interfaccia - o, per le reti remote come la LAN, tramite il next-hop indicato in tabella.
# --- ns-sofia ---
# equivalente di Sofia/nginx: ip address 10.10.10.2 + gateway 10.10.10.1
sudo ip netns exec ns-sofia ip link set lo up
sudo ip netns exec ns-sofia ip addr add 10.10.10.2/29 dev veth-sofia
sudo ip netns exec ns-sofia ip link set veth-sofia up
sudo ip netns exec ns-sofia ip route add default via 10.10.10.1
# --- ns-fw2 ---
# equivalente di FW2 Gig1/1 dmz: ip address 10.10.10.3 255.255.255.248 + no shutdown
sudo ip netns exec ns-fw2 ip link set lo up
sudo ip netns exec ns-fw2 ip addr add 10.10.10.3/29 dev veth-fw2-dmz
sudo ip netns exec ns-fw2 ip link set veth-fw2-dmz up
# equivalente di FW2 Gig1/2 inside: ip address 10.30.30.1 255.255.255.252 + no shutdown
sudo ip netns exec ns-fw2 ip addr add 10.30.30.1/30 dev veth-fw2-lan
sudo ip netns exec ns-fw2 ip link set veth-fw2-lan up
# equivalente di "route dmz 0.0.0.0 0.0.0.0 10.10.10.1"
sudo ip netns exec ns-fw2 ip route add default via 10.10.10.1
# --- ns-giulia ---
# equivalente di Giulia/MySQL: ip address 10.30.30.2 + gateway 10.30.30.1
sudo ip netns exec ns-giulia ip link set lo up
sudo ip netns exec ns-giulia ip addr add 10.30.30.2/30 dev veth-giulia
sudo ip netns exec ns-giulia ip link set veth-giulia up
sudo ip netns exec ns-giulia ip route add default via 10.30.30.1Verifica finale - tutti gli IP assegnati:
sudo ip netns exec ns-fw1 ip addr show
sudo ip netns exec ns-sofia ip addr show
sudo ip netns exec ns-fw2 ip addr show
sudo ip netns exec ns-giulia ip addr show# ns-fw1
9: veth-fw1-out@if10 inet 10.0.0.2/30 state UP
13: veth-fw1-dmz@if12 inet 10.10.10.1/29 state UP
# ns-sofia
15: veth-sofia@if14 inet 10.10.10.2/29 state UP
# ns-fw2
17: veth-fw2-dmz@if16 inet 10.10.10.3/29 state UP
19: veth-fw2-lan@if18 inet 10.30.30.1/30 state UP
# ns-giulia
18: veth-giulia@if19 inet 10.30.30.2/30 state UPTutti UP, tutti gli IP corretti. In Cisco Packet Tracer i triangoli sarebbero diventati verdi.
flowchart LR
classDef ext fill:#4a0d0d,stroke:#e05555,color:#eee
classDef hub fill:#1a1a2d,stroke:#8888cc,color:#eee
classDef fw fill:#0d1a3d,stroke:#4a9eff,color:#eee
classDef dmz fill:#3d2a0d,stroke:#ffaa4a,color:#eee
classDef lan fill:#0d2d15,stroke:#4aff7e,color:#eee
KALI["Kali
192.168.64.200"]:::ext
UBU["Ubuntu host
veth-host
10.0.0.1/30"]:::hub
subgraph FW1["ns-fw1"]
FW1OUT["veth-fw1-out
10.0.0.2/30"]:::fw
FW1DMZ["veth-fw1-dmz
10.10.10.1/29"]:::fw
end
BRDMZ{{"br-dmz
L2 bridge"}}:::hub
SOFIA["ns-sofia
veth-sofia
10.10.10.2/29"]:::dmz
subgraph FW2["ns-fw2"]
FW2DMZ["veth-fw2-dmz
10.10.10.3/29"]:::fw
FW2LAN["veth-fw2-lan
10.30.30.1/30"]:::fw
end
GIULIA[("ns-giulia
veth-giulia
10.30.30.2/30")]:::lan
KALI --- UBU --- FW1OUT
FW1OUT --- FW1DMZ
FW1DMZ --- BRDMZ
BRDMZ --- SOFIA
BRDMZ --- FW2DMZ
FW2DMZ --- FW2LAN
FW2LAN --- GIULIA
La topologia Linux e' identica al cisco-packet-tracer-dmz|lab Cisco a questo punto: dispositivi configurati, link attivi. Quello che in Cisco era ip address + no shutdown, in Linux e' ip addr add + ip link set up.
Rotte su Ubuntu e Kali#
Nel lab Cisco, Kali aveva 10.0.0.2 (FW1) come default gateway e raggiungeva tutto attraverso di esso. In Linux il percorso e' a due hop: Kali → Ubuntu → ns-fw1. Questo richiede rotte esplicite su entrambe le macchine.
Su Ubuntu host - Ubuntu sa solo raggiungere 10.0.0.0/30 via veth-host. Non conosce DMZ e LAN. Aggiungiamo le rotte puntando a ns-fw1 (10.0.0.2) come nexthop:
sudo ip route add 10.10.10.0/29 via 10.0.0.2 dev veth-host
sudo ip route add 10.30.30.0/30 via 10.0.0.2 dev veth-hostSu Kali - Kali ha solo la rotta per 10.0.0.0/30. Aggiungiamo DMZ e LAN via Ubuntu (192.168.64.3):
sudo ip route add 10.10.10.0/29 via 192.168.64.3
sudo ip route add 10.30.30.0/30 via 192.168.64.3Verifica su entrambe le macchine:
ip route listUbuntu dopo le aggiunte:
default via 192.168.64.1 dev enp0s1
10.0.0.0/30 dev veth-host proto kernel scope link src 10.0.0.1
10.10.10.0/29 via 10.0.0.2 dev veth-host
10.30.30.0/30 via 10.0.0.2 dev veth-host
192.168.64.0/24 dev enp0s1 proto kernel scope link src 192.168.64.3Kali dopo le aggiunte:
default via 192.168.64.1 dev eth0 onlink
10.0.0.0/30 via 192.168.64.3 dev eth0
10.10.10.0/29 via 192.168.64.3 dev eth0
10.30.30.0/30 via 192.168.64.3 dev eth0
192.168.64.0/24 dev eth0 proto kernel scope link src 192.168.64.200Con queste rotte Kali raggiunge ns-fw1 (10.10.10.1) con TTL=63 — un solo hop L3 (Ubuntu):
# da Kali
ping -c3 10.10.10.1
# 64 bytes from 10.10.10.1: icmp_seq=1 ttl=63 time=1.33 ms
# 3 packets transmitted, 3 received, 0% packet lossAnche queste rotte sono effimere — spariscono al reboot di Ubuntu e Kali, esattamente come i namespace. Lo script setup-dmz.sh le includere'.
mindmap
root((Rotte su Ubuntu e Kali))
Ubuntu host
Conosce solo 10.0.0.0/30
Aggiunge DMZ 10.10.10.0/29 via 10.0.0.2
Aggiunge LAN 10.30.30.0/30 via 10.0.0.2
Kali VM
Default via 192.168.64.1
Aggiunge 10.0.0.0/30 via Ubuntu
Aggiunge DMZ via Ubuntu
Aggiunge LAN via Ubuntu
Rotte effimere
Spariscono al reboot
Incluse in setup-dmz.sh
Verifica
ip route list
ip_forward - il kernel diventa un router#
Cisco: in cisco-packet-tracer-routing|Cinque Router, Una Catena, Nessun GPS ogni nodo della catena - Aldo, Marco, Sofia, Luca, Giulia - e' un router Cisco:
ip routinge' attivo di default su IOS, instrada sempre secondo la sua routing table, nessun interruttore da girare. Nel cisco-packet-tracer-dmz|lab DMZ invece Sofia/nginx e Giulia/MySQL sono PC - dispositivi che non instradano mai, per natura, anche se conoscono la rotta. FW1 e FW2 sono ASA, e instradano come i router della catena.In Linux non esiste questa distinzione "per tipo di dispositivo" - ogni namespace nasce come uno stack IP identico agli altri.
ip_forwarde' l'interruttore che decide se quel namespace si comporta come i router della catena (instrada sempre) o come un PC della DMZ (instrada solo se e' lui il destinatario).
ip_forward dice al kernel: "se ricevi un pacchetto che non e' destinato a te, non dropparlo - instradalo verso la destinazione giusta." Senza di esso ogni namespace si comporta come un host finale, non come un router.
La differenza e' tra L2 e L3. A livello 2 un'interfaccia riceve un frame se il MAC di destinazione e' il suo - vale per chiunque, host o router: e' l'ARP che risolve "chi ha questo IP" nel MAC giusto, a prescindere da cosa succedera' dopo. La domanda vera e' cosa fa il namespace a livello 3, quando l'IP di destinazione nel pacchetto non e' uno dei suoi: con ip_forward=0 lo droppa (comportamento host), con ip_forward=1 guarda la routing table e lo inoltra sull'interfaccia giusta (comportamento router).
Il comportamento senza ip_forward si capisce confrontando due ping da ns-fw1:
# ping verso ns-sofia (10.10.10.2) - stessa subnet DMZ, stesso bridge
sudo ip netns exec ns-fw1 ping -c3 10.10.10.2
# 64 bytes from 10.10.10.2: icmp_seq=1 ttl=64 time=0.107 ms <- FUNZIONA
# 64 bytes from 10.10.10.2: icmp_seq=2 ttl=64 time=0.114 ms
# 64 bytes from 10.10.10.2: icmp_seq=3 ttl=64 time=0.097 ms
# ping verso ns-giulia (10.30.30.2) - subnet diversa, richiede routing
sudo ip netns exec ns-fw1 ping -c3 10.30.30.2
# 3 packets transmitted, 0 received, 100% packet loss <- FALLISCEPerche' uno funziona e l'altro no: ns-sofia e' sulla stessa subnet 10.10.10.0/29 e sullo stesso bridge br-dmz. Il pacchetto viaggia a livello 2 - il bridge lo commuta direttamente in base al MAC, nessun routing necessario, nessun ip_forward coinvolto.
ns-giulia e' su una subnet diversa 10.30.30.0/30. ns-fw1 guarda la sua routing table, trova la rotta 10.30.30.0/30 via 10.10.10.3 e manda il pacchetto verso ns-fw2. A L2 ns-fw2 lo riceve regolarmente: l'ARP ha risolto 10.10.10.3 nel MAC di veth-fw2-dmz, il frame e' indirizzato a lui e lo prende. Ma a L3 ns-fw2 guarda l'IP di destinazione, 10.30.30.2, e non e' un suo indirizzo: senza ip_forward=1 lo droppa li'. Ricevere il frame (L2) e instradare il pacchetto (L3) sono due cose diverse - ed e' la seconda quella che manca.
In Cisco era la stessa logica: stessa VLAN = lo switch commuta senza coinvolgere il firewall. Subnet diversa = il pacchetto passa per l'ASA - che, essendo un ASA e non un PC, instrada sempre per natura: la security-level/ACL decide se PUO' farlo, non se SA farlo.
Il terzo caso e' Kali verso ns-fw1: il pacchetto arriva su Ubuntu ma Ubuntu lo droppa prima che entri nel namespace.
Su Kali la routing table e' corretta - la rotta c'e', i pacchetti partono:
# su Kali VM
sudo ip route add 10.0.0.0/30 via 192.168.64.3
ip route list
# default via 192.168.64.1 dev eth0 onlink
# 10.0.0.0/30 via 192.168.64.3 dev eth0 <- rotta verso il lab
# 192.168.64.0/24 dev eth0 proto kernel scope link src 192.168.64.200
ping -c3 10.0.0.2
# PING 10.0.0.2 (10.0.0.2) 56(84) bytes of data.
# 3 packets transmitted, 0 received, 100% packet loss, time 2029msI pacchetti escono da Kali, arrivano su Ubuntu (192.168.64.3), ma Ubuntu con ip_forward=0 li droppa: la destinazione 10.0.0.2 non e' una sua interfaccia, quindi li scarta invece di girarli a ns-fw1 tramite veth-host.
Per abilitarlo nei namespace che fanno da router:
# host namespace: Ubuntu deve poter girare i pacchetti di Kali verso ns-fw1.
# senza questo, i pacchetti di Kali arrivano su enp0s1 e vengono droppati
# prima ancora di entrare nel namespace
sudo sysctl -w net.ipv4.ip_forward=1
# ns-fw1: deve poter instradare tra la sua interfaccia outside (10.0.0.2)
# e la sua interfaccia dmz (10.10.10.1) — equivalente del routing interno dell'ASA
sudo ip netns exec ns-fw1 sysctl -w net.ipv4.ip_forward=1
# ns-fw2: deve poter instradare tra dmz (10.10.10.3) e lan (10.30.30.1).
# e' il passaggio critico: senza questo ns-giulia e' irraggiungibile da qualsiasi zona
sudo ip netns exec ns-fw2 sysctl -w net.ipv4.ip_forward=1Con ip_forward attivo su tutti e tre, i TTL raccontano esattamente cosa sta succedendo:
# ns-fw1 → ns-sofia (10.10.10.2) — stesso bridge L2
sudo ip netns exec ns-fw1 ping -c3 10.10.10.2
# 64 bytes from 10.10.10.2: ttl=64 <- TTL intatto, nessun hop di routing
# ns-fw1 → ns-giulia (10.30.30.2) — attraversa ns-fw2
sudo ip netns exec ns-fw1 ping -c3 10.30.30.2
# 64 bytes from 10.30.30.2: ttl=63 <- TTL decrementato di 1: ns-fw2 ha instradato
# Kali → ns-fw1 (10.0.0.2) — attraversa Ubuntu host
ping -c3 10.0.0.2
# 64 bytes from 10.0.0.2: ttl=63 <- TTL decrementato di 1: Ubuntu host ha instradatoTTL=64: il pacchetto ha viaggiato solo a L2, nessun router coinvolto. TTL=63: un hop L3 - un namespace (o Ubuntu host) ha fatto da router e decrementato il TTL.
Il TTL e' 63, non 64 - e' la prova che ip_forward sta funzionando.
packet-beta
0-3: "Version (4)"
4-7: "IHL"
8-15: "DSCP / ECN"
16-31: "Total Length"
32-47: "Identification"
48-50: "Flags"
51-63: "Fragment Offset"
64-71: "TTL ← decrementa ad ogni hop"
72-79: "Protocol"
80-95: "Header Checksum"
96-127: "Source IP"
128-159: "Destination IP"
TTL: cos'e' e perche' parte da 64
TTL (Time To Live) e' un contatore nel header IP che impedisce ai pacchetti di girare in loop all'infinito. Ogni router che instrada il pacchetto lo decrementa di 1. Quando arriva a 0, il pacchetto viene droppato e il mittente riceve un messaggio ICMP "Time Exceeded".
Linux usa 64 come valore di default per convenzione storica (RFC 791 non imponeva un valore specifico). E' una potenza di 2 sufficiente per attraversare qualsiasi rete reale - internet ha mediamente 15-20 hop. Windows usa 128, Cisco router usano 255.
Perche' 63 prova che ip_forward funziona: il pacchetto e' partito da Kali con TTL=64. Ubuntu l'ha ricevuto su enp0s1 e instradato verso ns-fw1 tramite veth-host - questo e' un hop L3, quindi TTL decrementato a 63. Se Kali e ns-fw1 fossero sullo stesso segmento L2 diretto, non ci sarebbe nessun hop di routing e il TTL arriverebbe intatto a 64.
Il TTL e' anche una tecnica di OS fingerprinting: se ricevi una risposta con TTL=64 il sistema e' probabilmente Linux, TTL=128 e' Windows, TTL=255 e' un router Cisco. Strumenti come nmap usano questo per identificare il sistema operativo remoto senza inviare nessuna probe specifica.
Wazuh/Docker e ip_forward
Sul server di lab ip_forward era gia' abilitato in tutti i namespace prima che lo configurassimo — Docker lo abilita a livello di sistema all'avvio perche' ne ha bisogno per il networking dei container, e i nuovi namespace Linux ereditano quel valore.
Per fare la lezione in modo pulito lo abbiamo disabilitato manualmente:
sudo sysctl -w net.ipv4.ip_forward=0
sudo ip netns exec ns-fw1 sysctl -w net.ipv4.ip_forward=0
sudo ip netns exec ns-fw2 sysctl -w net.ipv4.ip_forward=0In un ambiente senza Docker questo passaggio non sarebbe necessario — ip_forward sarebbe 0 per default.
Ping matrix - chi raggiunge chi e perche'#
Tutti i test qui sotto sono eseguiti prima di iptables -P FORWARD DROP — nessuna regola ancora, ip_forward attivo su tutti i namespace. L'obiettivo e' mappare il comportamento di default della rete prima di mettere i muri.
Test 1 - Kali → ns-fw1 (10.0.0.2)#
| Mittente | Kali VM 192.168.64.200 |
| Destinazione | ns-fw1 10.0.0.2 |
| TTL ricevuto | 63 |
| Risultato | FUNZIONA |
# da Kali VM
ping -c3 10.0.0.2
# 64 bytes from 10.0.0.2: icmp_seq=1 ttl=63 time=2.08 ms
# 3 packets transmitted, 3 received, 0% packet lossTTL=63: Ubuntu host ha fatto un hop L3 — ha ricevuto il pacchetto su enp0s1 e lo ha girato verso ns-fw1 tramite veth-host.
mindmap
root((Test 1))
Kali a ns-fw1
TTL 63
Un hop L3 Ubuntu
Risultato PASS
Test 2 - Kali → ns-sofia (10.10.10.2)#
| Mittente | Kali VM 192.168.64.200 |
| Destinazione | ns-sofia 10.10.10.2 |
| TTL ricevuto | 62 |
| Risultato | FUNZIONA |
# da Kali VM
ping -c3 10.10.10.2
# 64 bytes from 10.10.10.2: icmp_seq=1 ttl=62 time=2.52 ms
# 3 packets transmitted, 3 received, 0% packet lossTTL=62: due hop L3 — Ubuntu instrada verso ns-fw1, ns-fw1 instrada verso ns-sofia tramite br-dmz.
mindmap
root((Test 2))
Kali a ns-sofia
TTL 62
Due hop Ubuntu poi ns-fw1
Risultato PASS
Test 3 - Kali → ns-giulia (10.30.30.2)#
| Mittente | Kali VM 192.168.64.200 |
| Destinazione | ns-giulia 10.30.30.2 |
| TTL ricevuto | 61 |
| Risultato | FUNZIONA |
# da Kali VM
ping -c3 10.30.30.2
# 64 bytes from 10.30.30.2: icmp_seq=1 ttl=61 time=8.10 ms
# 3 packets transmitted, 3 received, 0% packet lossTTL=61: tre hop L3 — Ubuntu → ns-fw1 → ns-fw2 → ns-giulia. Il TTL e' una mappa del percorso: ogni decremento e' un router attraversato.
| Destinazione | TTL | Hop |
|---|---|---|
ns-fw1 10.0.0.2 | 63 | Ubuntu |
ns-sofia 10.10.10.2 | 62 | Ubuntu → ns-fw1 |
ns-giulia 10.30.30.2 | 61 | Ubuntu → ns-fw1 → ns-fw2 |
mindmap
root((Test 3))
Kali a ns-giulia
TTL 61
Tre hop Ubuntu ns-fw1 ns-fw2
Risultato PASS
Test 4 - ns-sofia → ns-fw1 (10.10.10.1)#
| Mittente | ns-sofia 10.10.10.2 |
| Destinazione | ns-fw1 10.10.10.1 |
| TTL ricevuto | 64 |
| Risultato | FUNZIONA |
sudo ip netns exec ns-sofia ping -c3 10.10.10.1
# 64 bytes from 10.10.10.1: icmp_seq=1 ttl=64 time=0.050 ms
# 3 packets transmitted, 3 received, 0% packet lossTTL=64: stesso bridge br-dmz, nessun hop L3 — il frame e' commutato direttamente a livello 2.
mindmap
root((Test 4))
ns-sofia a ns-fw1
TTL 64 intatto
Stesso bridge L2
Risultato PASS
Test 5 - ns-sofia → ns-fw2 (10.10.10.3)#
| Mittente | ns-sofia 10.10.10.2 |
| Destinazione | ns-fw2 10.10.10.3 |
| TTL ricevuto | 64 |
| Risultato | FUNZIONA |
sudo ip netns exec ns-sofia ping -c3 10.10.10.3
# 64 bytes from 10.10.10.3: icmp_seq=1 ttl=64 time=0.218 ms
# 3 packets transmitted, 3 received, 0% packet lossTTL=64: ns-fw1, ns-sofia e ns-fw2 sono tutti sul bridge br-dmz — stesso segmento L2, nessun routing.
mindmap
root((Test 5))
ns-sofia a ns-fw2
TTL 64 intatto
Stesso bridge L2 br-dmz
Risultato PASS
Test 6 - ns-sofia → host esterno (10.0.0.1)#
| Mittente | ns-sofia 10.10.10.2 |
| Destinazione | veth-host 10.0.0.1 |
| TTL ricevuto | 63 |
| Risultato | FUNZIONA |
sudo ip netns exec ns-sofia ping -c3 10.0.0.1
# 64 bytes from 10.0.0.1: icmp_seq=1 ttl=63 time=1.37 ms
# 3 packets transmitted, 3 received, 0% packet lossTTL=63: ns-sofia usa il default route via ns-fw1 (un hop L3), poi ns-fw1 consegna direttamente su 10.0.0.0/30 dove vive veth-host.
mindmap
root((Test 6))
ns-sofia a veth-host
TTL 63
Un hop L3 ns-fw1
Risultato PASS
Test 7 - ns-sofia → ns-giulia (10.30.30.2)#
| Mittente | ns-sofia 10.10.10.2 |
| Destinazione | ns-giulia 10.30.30.2 |
| TTL ricevuto | 63 |
| Risultato | FUNZIONA |
sudo ip netns exec ns-sofia ping -c3 10.30.30.2
# From 10.10.10.1: icmp_seq=1 Redirect Host(New nexthop: 10.10.10.3)
# 64 bytes from 10.30.30.2: icmp_seq=1 ttl=63 time=0.209 ms
# 3 packets transmitted, 3 received, 0% packet lossTTL=63: un hop L3 attraverso ns-fw2. ns-fw1 invia un ICMP Redirect — ns-sofia ha default route via ns-fw1 (10.10.10.1), ma ns-fw1 si accorge che il nexthop corretto (ns-fw2 10.10.10.3) e' sullo stesso bridge e suggerisce a ns-sofia di andarci direttamente. In produzione si disabilita: e' un vettore di attacco per dirottare il traffico. Su ASA Cisco e' disabilitato per default.
mindmap
root((Test 7))
ns-sofia a ns-giulia
TTL 63
Un hop L3 ns-fw2
ICMP Redirect da ns-fw1
Risultato PASS
Attenzione
Redirect vettore di attacco
Disabilitare in produzione
Test 8 - ns-giulia → ns-fw2 (10.30.30.1)#
| Mittente | ns-giulia 10.30.30.2 |
| Destinazione | ns-fw2 10.30.30.1 |
| TTL ricevuto | 64 |
| Risultato | FUNZIONA |
sudo ip netns exec ns-giulia ping -c3 10.30.30.1
# 64 bytes from 10.30.30.1: icmp_seq=1 ttl=64 time=0.056 ms
# 3 packets transmitted, 3 received, 0% packet lossTTL=64: stesso link /30 diretto tra ns-giulia e ns-fw2, nessun hop di routing.
mindmap
root((Test 8))
ns-giulia a ns-fw2
TTL 64 intatto
Link diretto su 10.30.30.0/30
Risultato PASS
Test 9 - ns-giulia → ns-sofia (10.10.10.2)#
| Mittente | ns-giulia 10.30.30.2 |
| Destinazione | ns-sofia 10.10.10.2 |
| TTL ricevuto | 62 |
| Risultato | FUNZIONA |
sudo ip netns exec ns-giulia ping -c3 10.10.10.2
# 64 bytes from 10.10.10.2: icmp_seq=1 ttl=62 time=0.111 ms
# 3 packets transmitted, 3 received, 0% packet lossTTL=62: il ping mostra il TTL della risposta, non della richiesta. La risposta parte da ns-sofia con TTL=64 e attraversa due hop L3 prima di arrivare a ns-giulia: ns-sofia usa il default route via ns-fw1 (primo hop, TTL→63), poi ns-fw1 instrada verso ns-fw2 (secondo hop, TTL→62), e ns-fw2 consegna a ns-giulia sullo stesso link diretto.
mindmap
root((Test 9))
ns-giulia a ns-sofia
TTL 62 della risposta
Due hop ns-fw2 poi ns-fw1
Risultato PASS
Riepilogo ping matrix#
| Test | Mittente | Destinazione | TTL | Hop |
|---|---|---|---|---|
| 1 | Kali | ns-fw1 10.0.0.2 | 63 | Ubuntu |
| 2 | Kali | ns-sofia 10.10.10.2 | 62 | Ubuntu → ns-fw1 |
| 3 | Kali | ns-giulia 10.30.30.2 | 61 | Ubuntu → ns-fw1 → ns-fw2 |
| 4 | ns-sofia | ns-fw1 10.10.10.1 | 64 | L2 bridge |
| 5 | ns-sofia | ns-fw2 10.10.10.3 | 64 | L2 bridge |
| 6 | ns-sofia | veth-host 10.0.0.1 | 63 | ns-fw1 |
| 7 | ns-sofia | ns-giulia 10.30.30.2 | 63 | ns-fw2 |
| 8 | ns-giulia | ns-fw2 10.30.30.1 | 64 | link diretto |
| 9 | ns-giulia | ns-sofia 10.10.10.2 | 62 | ns-fw2 → ns-fw1 (reply) |
Tutti FUNZIONANO — nessuna regola iptables ancora. Il prossimo passo: iptables -P FORWARD DROP. Da questo momento tutto e' bloccato per default e apriremo solo quello che serve, esattamente come fa un ASA Cisco per default.
flowchart LR
classDef ext fill:#4a0d0d,stroke:#e05555,color:#eee
classDef hub fill:#1a1a2d,stroke:#8888cc,color:#eee
classDef fw fill:#0d1a3d,stroke:#4a9eff,color:#eee
classDef dmz fill:#3d2a0d,stroke:#ffaa4a,color:#eee
classDef lan fill:#0d2d15,stroke:#4aff7e,color:#eee
KALI["Kali
TTL=64"]:::ext
UBU["Ubuntu host
L3 — TTL 64→63"]:::hub
FW1["ns-fw1
10.0.0.2
TTL=63 in, L3 — TTL 63→62"]:::fw
BRDMZ{{"br-dmz
L2 bridge
TTL invariato"}}:::hub
SOFIA["ns-sofia
10.10.10.2
TTL=62"]:::dmz
FW2["ns-fw2
10.10.10.3
TTL=62 in, L3 — TTL 62→61"]:::fw
GIULIA[("ns-giulia
10.30.30.2
TTL=61")]:::lan
KALI --> UBU --> FW1 --> BRDMZ
BRDMZ --> SOFIA
BRDMZ --> FW2 --> GIULIA
mindmap
root((Riepilogo ping matrix))
Da Kali
ns-fw1 TTL 63 uno hop
ns-sofia TTL 62 due hop
ns-giulia TTL 61 tre hop
Da ns-sofia
ns-fw1 TTL 64 L2 bridge
ns-fw2 TTL 64 L2 bridge
veth-host TTL 63 ns-fw1
ns-giulia TTL 63 ns-fw2
Da ns-giulia
ns-fw2 TTL 64 link diretto
ns-sofia TTL 62 reply via ns-fw2 ns-fw1
I namespace sono volatili - lo script#
A differenza di Packet Tracer che salva il file .pkt, i namespace Linux vivono in memoria. Spegni la VM, sparisce tutto.
La soluzione sono due script bash che replicano tutto quello che abbiamo fatto nel lab:
wip.sh — da eseguire su Ubuntu come sudo bash wip.sh. Ricrea in 8 step interattivi:
- Namespace (ns-fw1, ns-sofia, ns-fw2, ns-giulia)
- Veth pair e bridge DMZ
- Indirizzi IP + rotta statica Sofia→LAN via ns-fw2
- Rotte Ubuntu host verso DMZ e LAN
- ip_forward su host, ns-fw1, ns-fw2
- Fix FORWARD chain host (Docker/ufw)
- iptables default DROP + ACL porta 80 e 443 su ns-fw1
- iptables ACL porta 3306 su ns-fw2 (solo da ns-sofia)
Ogni step mostra i comandi prima di eseguirli e aspetta INVIO — pensato per ripassare la topologia passo per passo, non solo per l'automazione.
wip_kali.sh — da eseguire su Kali come sudo bash wip_kali.sh. Aggiunge le tre rotte necessarie per raggiungere le subnet del lab:
ip route add 10.0.0.0/30 via 192.168.64.3 # link esterno: host <-> ns-fw1
ip route add 10.10.10.0/29 via 192.168.64.3 # DMZ
ip route add 10.30.30.0/30 via 192.168.64.3 # LANCosa non e' nello script — nginx, ModSecurity e la configurazione Wazuh non sono riproducibili da zero con un bash: richiedono pacchetti installati (apt install nginx libnginx-mod-http-modsecurity), file di configurazione già presenti e il CRS clonato. Questi step vanno eseguiti manualmente seguendo le sezioni del lab. Lo script ricrea solo la topologia di rete — il layer L3/L4.
Script e file di configurazione del lab: github.com/Barno/u-random-dev
mindmap
root((Namespace volatili e script))
Problema
Namespace vivono in memoria
Spegni VM sparisce tutto
Soluzione
wip.sh su Ubuntu 8 step interattivi
wip kali.sh su Kali 3 rotte
Cosa ricrea wip.sh
Namespace e veth pair
IP e rotte
ip forward
Fix FORWARD chain host
iptables DROP e ACL
Cosa non e' nello script
nginx e ModSecurity
Pacchetti e configurazioni
Solo topologia L3 L4