mindmap
root((Cap 5
Securing Hosts
and Data))
Virtualization
Implementing Secure Systems
Protecting Data
Cloud Concepts
Hardening Cloud Environments
Mobile Devices
Embedded Systems
Cosa fa#
Risponde alla domanda: cosa devi proteggere quando il perimetro non esiste piu'? Il capitolo copre sette superfici di attacco distinte — virtualizzazione, endpoint, dati, cloud, mobile, IoT, sistemi embedded — ciascuna con le sue vulnerabilita', i suoi controlli e le sue trappole da esame.
TL;DR#
Il perimetro tradizionale era il firewall ai bordi della rete. Cap 5 mostra che il perimetro si e' frammentato: oggi devi proteggere host fisici, VM, container, dati a riposo/in transito/in uso, workload cloud SaaS/PaaS/IaaS, smartphone BYOD, sensori IoT, impianti SCADA industriali. Sette superfici, sette insiemi di controlli diversi.
SUPERFICI DI ATTACCO — Cap 5
Fisico VM / Container Cloud Mobile + IoT
-------- -------------- ----- ------------
Host Hypervisor SaaS BYOD / COPE
TPM/UEFI VM Escape PaaS MDM / UEM
FDE/SED VM Sprawl IaaS Jailbreak
HSM Container escape CASB Embedded OS
Patch Snapshot SWG SCADA/ICS
Decommission Replication IaC/SDN Air-gapPattern ricorrente dell'esame:
- Virtualizzazione: VM Escape (attacco) vs VM Sprawl (problema gestione). Non confonderli.
- Cloud: il Shared Responsibility Model decide chi e' responsabile di cosa in SaaS/PaaS/IaaS. Exam keyword: "who is responsible for...".
- CASB vs SWG: CASB tra utente e cloud aziendale; SWG tra utente e internet generico.
- Mobile: chi possiede il dispositivo = BYOD (utente) / COPE (azienda) / CYOD (sceglie utente, paga azienda). Trappola classica.
- ICS/SCADA: CIA triad invertita — Availability prima di tutto. Un impianto fermo e' piu' pericoloso di dati esposti.
- Dati: tre stati (at rest, in transit, in use). I controlli cambiano per ogni stato.
Virtualization#
mindmap
root((Virtualization))
Hypervisor e Host
Type 1 bare-metal
Type 2 hosted
Host fisico
Guest VM
Scalability vs Elasticity
Scalability manuale
Elasticity automatica
VDI e Thin Client
Desktop su server
Zero data on device
Containerization
Kernel condiviso
Docker
Piu leggero di VM
Rischi
VM Escape
Patch hypervisor
VM Sprawl
Change management
Resource Reuse
Memory overcommit
Resilienza
Replication altro server
Snapshot stesso server
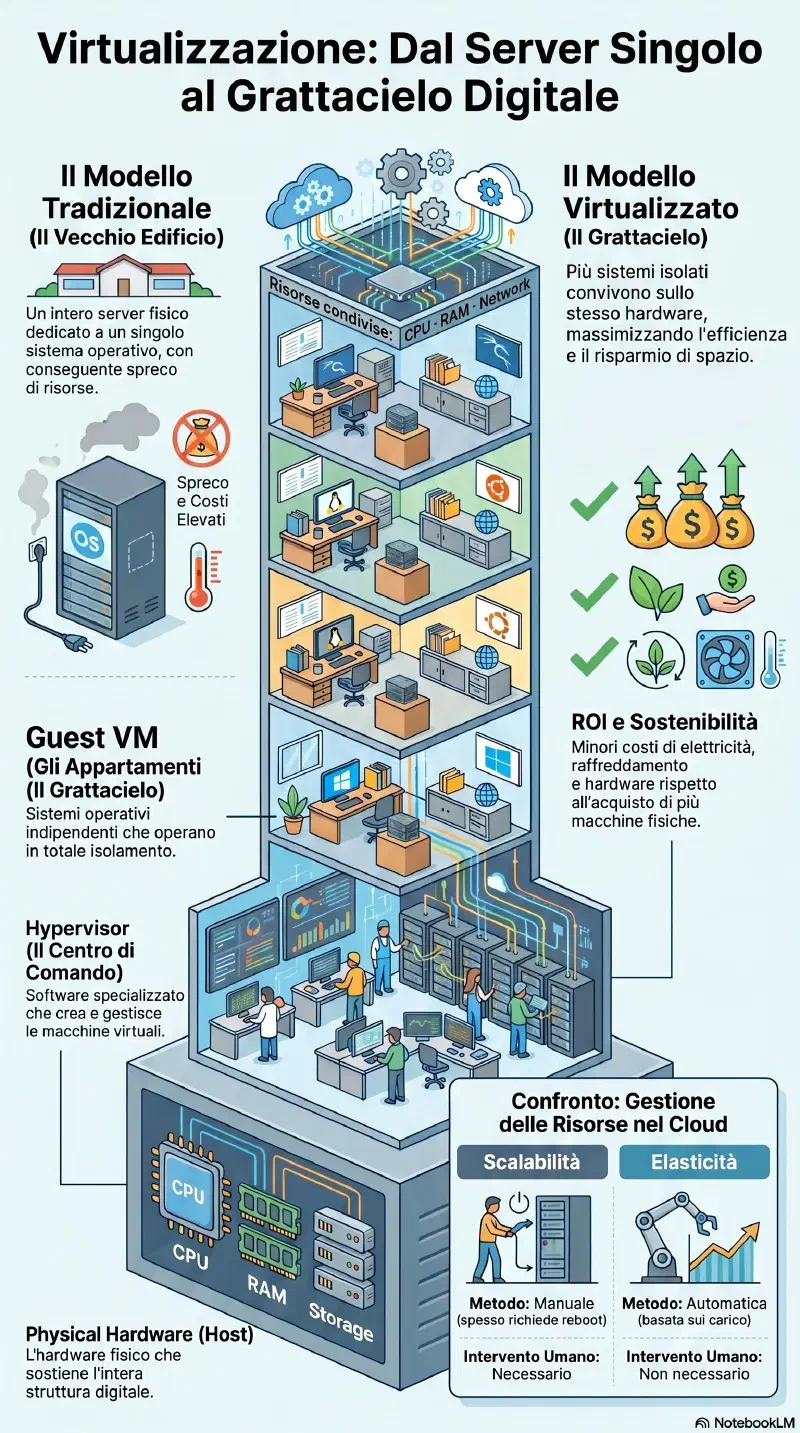
La virtualizzazione permette di ospitare uno o piu' sistemi virtuali su un singolo sistema fisico. Con le tecnologie attuali e' possibile virtualizzare un'intera rete su un solo host fisico.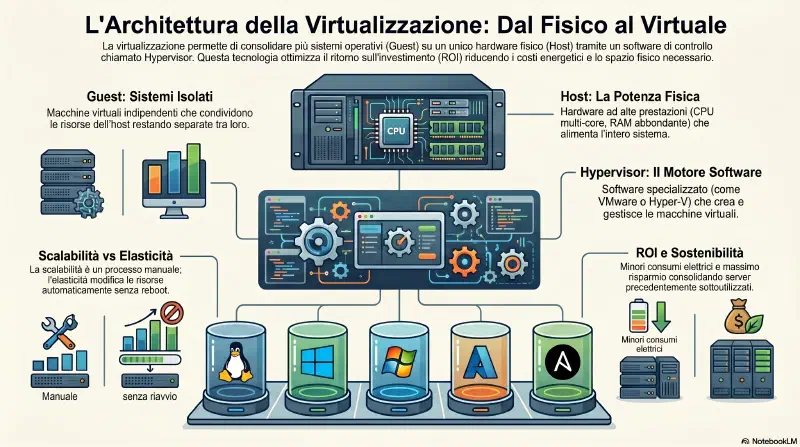
Hypervisor#
Software specializzato che crea, avvia e gestisce le VM. Esempi: VMware, Microsoft Hyper-V, Oracle VirtualBox, UTM (su Apple Silicon). L'hypervisor e' il motore di tutto.
Host#
La macchina fisica che esegue l'hypervisor. Richiede risorse superiori a un sistema normale: processori multi-core veloci, molta RAM, storage rapido e abbondante, schede di rete veloci. Il costo e' piu' alto di un PC normale, ma resta inferiore a comprare N macchine fisiche separate. Consuma meno elettricita', richiede meno raffreddamento e meno spazio fisico.
I VPS (Virtual Private Server) su Hetzner, DigitalOcean ecc. sono guest che girano su un host fisico del provider. Tu usi la VM (guest), loro gestiscono l'hardware (host). Il Mustache Project su Hetzner funziona esattamente cosi'.
Guest#
I sistemi operativi che girano virtualizzati sull'host sono chiamati guest o guest machine. Ogni guest e' isolato dagli altri. La maggior parte degli hypervisor supporta Windows, Linux, sistemi a 32 e 64 bit.
Il lab UTM e' l'esempio perfetto: host = Mac, guest = Ubuntu Server + Kali Linux. Quando fai ARP poisoning, i due guest comunicano come macchine fisiche distinte.
Cloud Scalability#
Capacita' di ridimensionare le risorse di una VM: piu' CPU, RAM, disco, banda. E' un processo manuale che richiede l'intervento di un amministratore, spesso con reboot.
Cloud Elasticity#
Capacita' di modificare automaticamente le risorse in base al carico, senza intervento umano e senza reboot. Il monitoring rileva il picco e scala in tempo reale. AWS Auto Scaling e GCP Autoscaler funzionano cosi'.
| Caratteristica | Scalability | Elasticity |
|---|---|---|
| Trigger | Manuale (admin) | Automatico (monitoring) |
| Reboot necessario | Spesso si | No |
| Adattamento al carico | No | Si, in tempo reale |
| Esempi | Aggiungere RAM a una VM | AWS Auto Scaling |
Esame Security+: la parola chiave e' automatico vs manuale. Elasticity = automatico, no reboot. Scalability = manuale, spesso richiede reboot.
ROI della virtualizzazione#
Da' il miglior ritorno sull'investimento quando ci sono molti server sottoutilizzati. Esempio Gibson: 9 server fisici ognuno al 20% di utilizzo si consolidano come VM su 2-3 server fisici. Si risparmia su hardware, elettricita', raffreddamento, spazio nel rack.
Thin Clients and Virtual Desktop Infrastructure#
Un thin client e' un computer con il minimo delle risorse per avviarsi e connettersi a un server. Ha tastiera, mouse, schermo e poco piu'. Il server (on-site o cloud) fa tutto il lavoro pesante e supporta piu' thin client in parallelo.
VDI (Virtual Desktop Infrastructure) porta questo concetto un passo avanti: il desktop OS completo dell'utente gira su un server, non sulla macchina fisica. L'utente vede e interagisce con il suo desktop, ma tutta la computazione avviene sul server. Si puo' accedere via browser, app o dispositivo mobile, con VPN per l'accesso remoto.
VDI vs TeamViewer / VNC: l'esperienza e' identica — vedi uno schermo remoto, i tuoi clic e la tastiera viaggiano verso il server, lui elabora e ti rimanda i pixel. La differenza e' cosa c'e' dall'altra parte: con TeamViewer controlli una macchina fisica che esiste da qualche parte. Con VDI controlli una macchina virtuale che vive sul server — nessun hardware dedicato, nessun computer fisico. Stacchi la VDI e il desktop resta sospeso sul server, pronto alla prossima connessione.
| TeamViewer | VDI | |
|---|---|---|
| Macchina remota | Fisica | Virtuale (sul server) |
| Dove stanno i dati | Sulla macchina remota | Sul server centrale — zero data on device |
| Gestione | Per macchina, separata | Centralizzata — patchi un template, si propaga a tutti |
| Caso d'uso | Accesso/supporto remoto | Desktop aziendale scalabile e sicuro |
Zero data on device e' il vantaggio di sicurezza principale di VDI: se perdi o ti rubano il laptop thin client, non ci sono dati da esfiltare. Rilevante per DLP e ambienti ad alta compliance.
Containerization#
La containerizzazione e' una forma di virtualizzazione che esegue servizi o applicazioni in container isolati. Docker e' l'esempio piu' noto.
La differenza critica rispetto alle VM classiche: i container non includono un SO completo. Condividono il kernel dell'host. Ogni container ha il suo filesystem isolato, ma gira direttamente sul kernel host. Questo li rende molto piu' leggeri e veloci da avviare rispetto a una VM.
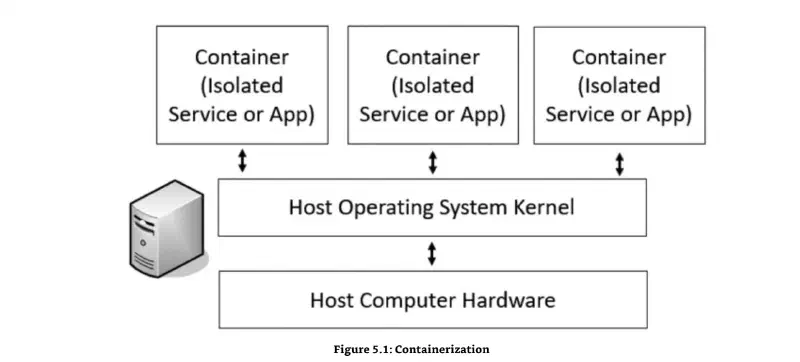
Vantaggi: usa meno risorse rispetto a un hypervisor tradizionale, piu' efficiente, gli ISP lo usano per isolare i servizi dei clienti.
Vincolo importante: i container devono usare lo stesso OS dell'host. Se l'host e' Linux, tutti i container girano Linux. Non puoi mescolare.
OS (Operating System): software che fa da intermediario tra hardware e applicazioni. Gestisce CPU, RAM, disco, rete. Il kernel e' il cuore dell'OS — il pezzo che parla direttamente con l'hardware. Esempi: Linux, Windows, macOS. Quando Gibson dice "i container condividono il kernel dell'host", intende che condividono proprio questo strato basso.
Filesystem: il sistema che organizza e struttura i file su disco. Definisce come i dati vengono scritti, letti, nominati e organizzati in cartelle. Esempi: ext4 (Linux), NTFS (Windows), APFS (macOS). Ogni container ha il proprio filesystem isolato (vede solo i suoi file), ma usa il kernel dell'host per operarci sopra. E' come avere cassetti separati nella stessa cassettiera.
| VM (Hypervisor) | Container | |
|---|---|---|
| SO per istanza | Completo (kernel proprio) | No (kernel condiviso) |
| Isolamento | Forte | Buono ma meno completo |
| Peso / startup | Pesante, lento | Leggero, veloce |
| Esempio | UTM con Ubuntu | Docker |
| Vincolo OS | No | Si, stesso OS dell'host |
| Docker non e' la "naturale evoluzione" di una VM. Virtualizzano livelli diversi dello stack: |
| VM | Container | |
|---|---|---|
| Virtualizza | Hardware | OS (namespace + cgroups) |
| Kernel | Proprio per ogni VM | Condiviso con l'host |
| Isolamento | Forte — VM escape e' difficile | Piu' leggero — container escape piu' probabile |
| Avvio | Minuti | Millisecondi |
| Dimensione | GB | MB |
| Caso d'uso tipico | Ambienti completamente separati | Processi isolati sullo stesso OS |
VM Escape Protection#
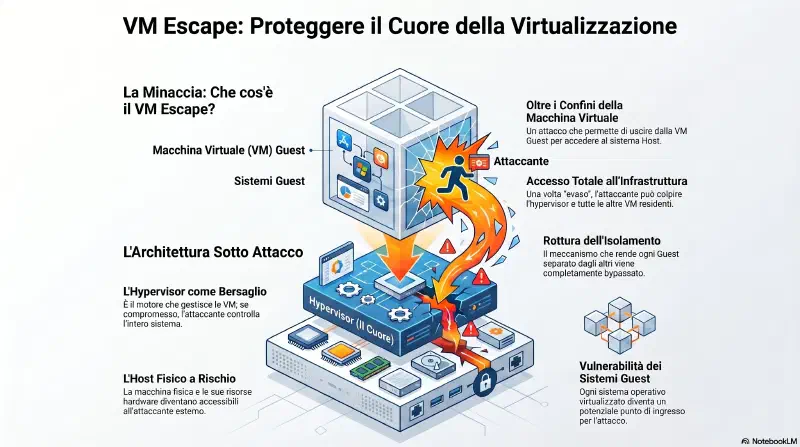
Il dettaglio critico e' quello dei privilegi: l'hypervisor gira con privilegi elevati, equivalenti a quelli di amministratore. Un attacco VM escape riuscito non da' accesso solo all'host — da' controllo illimitato su host e su ogni singola VM guest. E' come bucare il soffitto del tuo appartamento e atterrare nel vano tecnico del grattacielo intero: da li' controlli riscaldamento, elettricita', ascensori — tutto.
VM escape e' uno degli attacchi piu' gravi in ambiente virtualizzato. Un singolo guest compromesso che riesce a fare escape compromette l'intero host e tutte le VM sorelle.
Difesa: patch, patch, patch. Quando i vendor scoprono vulnerabilita' VM escape rilasciano patch. Vanno applicate il prima possibile sia sui server fisici che su quelli virtuali.
Exam tip Gibson: "Keeping systems up to date with current patches is the best protection from VM escape attacks."
Esempio reale — Pwn2Own 2017: La chain di attacco dimostra perfettamente come funziona un VM escape in pratica.
1. Bug nel motore JavaScript di Microsoft Edge
↓ accesso alla sandbox del browser
2. Exploit del kernel di Windows 10
↓ controllo completo del guest OS
3. Bug di simulazione hardware in VMware
↓ salto a un'altra VM sullo stesso hypervisorTre vulnerabilita' concatenate, tre vendor diversi (Microsoft Edge, Microsoft OS, VMware). Ognuna singolarmente non basta — insieme danno controllo su tutte le VM dell'hypervisor. VMware ha patchato prima che l'exploit fosse usato in produzione.
VM Sprawl Avoidance#
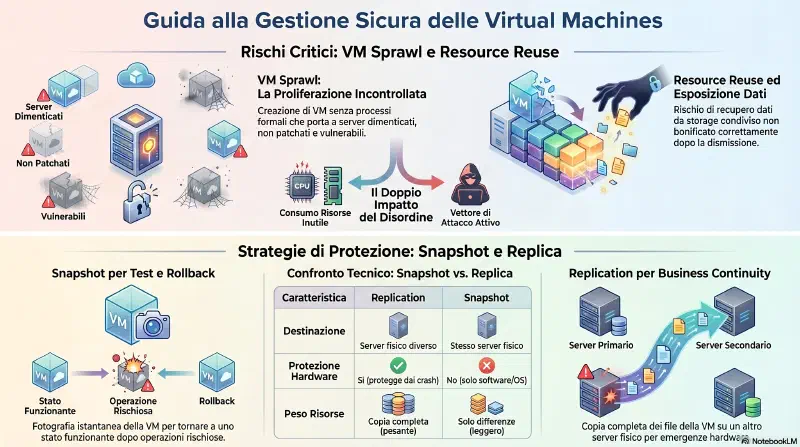
Esempio Gibson: Bart crea una VM per testare un'applicazione. Finito il test, la lascia accesa. Il reparto IT applica le patch a tutti i server conosciuti — ma la VM di Bart non e' nei registri, resta non patchata e vulnerabile.
Doppio problema:
- Sicurezza: VM non patchate = vettori di attacco attivi
- Risorse: ogni VM aggiunge carico sul server fisico. Troppe VM non autorizzate possono rallentare o far crashare il server
Difesa: le stesse policy che governano i server fisici devono applicarsi alle VM — change management, inventario, approvazione prima della creazione.
Resource Reuse#
Resource reuse e' un rischio di esposizione passiva: risorse fisiche condivise tra VM diverse possono contenere dati residui del precedente utente.
RAM — memory overcommit L'hypervisor puo' allocare piu' RAM virtuale di quanta ce ne sia fisicamente. Esempio:
Host fisico: 4 GB RAM
VM1: allocati 2 GB ─┐
VM2: allocati 2 GB ├─ totale allocato = 6 GB > 4 GB fisici
VM3: allocati 2 GB ─┘Funziona perche' non tutte le VM usano tutta la RAM allocata simultaneamente. L'hypervisor sposta i blocchi di memoria fisica tra le VM dinamicamente.
Il rischio: quando una VM libera un blocco di memoria, quel blocco puo' essere riassegnato a un'altra VM. Se l'hypervisor ha un bug e non azzera il blocco prima della riassegnazione, la nuova VM potrebbe leggere i dati della precedente.
VM1 scrive in blocco X: "password=admin123"
VM1 libera blocco X
Hypervisor (bug) → assegna blocco X a VM2 senza azzerarlo
VM2 legge blocco X → trova "password=admin123"Storage cloud Stesso rischio su disco: quando un cliente smette di usare una VM, lo storage fisico non viene necessariamente azzerato prima di essere riassegnato a un altro cliente. Nel cloud non hai accesso all'hardware — non puoi verificare che sia stato pulito.
Analogia: affitti una cassaforte in banca, la restituisci, il prossimo inquilino potrebbe trovare ancora i tuoi appunti dentro.
Difesa: patch all'hypervisor per bug di memory management; contratti con il cloud provider con obblighi di secure erasure.
Resource reuse non e' un attacco attivo — e' un rischio di esposizione passiva. I dati rimangono leggibili per mancata cancellazione sicura delle risorse condivise, non per azione diretta di un attaccante.
Replication#
Le VM sono semplicemente file. File complessi, ma pur sempre file. Questo le rende facili da replicare: copi i file da un server fisico a un altro e hai un backup funzionante.
Se la VM originale si danneggia, ripristini i file replicati. Il tempo di ripristino si misura in minuti — contro le ore necessarie per ricostruire un server fisico da zero.
| Replication | Snapshot | |
|---|---|---|
| Dove vive la copia | Server fisico diverso | Stesso server |
| Protegge da crash hardware | Si | No |
| Peso | Copia completa (pesante) | Solo delta (leggero) |
| Analogia | git push su GitHub | git commit in locale |
Snapshots#
Uno snapshot e' una fotografia della VM in un momento preciso. L'hypervisor registra tutte le modifiche successive — se qualcosa va storto, puoi tornare esattamente allo stato in cui era la VM quando hai scattato la foto.
Gli amministratori fanno snapshot prima di operazioni rischiose: applicare patch, testare security control, installare nuove applicazioni. Se l'operazione causa problemi, rollback in pochi secondi a uno stato noto e funzionante. Quando scatti uno snapshot, l'hypervisor congela lo stato e da quel momento in poi tutte le scritture successive vanno in un file delta separato. Se torni indietro, applichi il rollback del delta. In questo senso e' "incrementale dopo il punto di snapshot".
Snapshot = rete di sicurezza prima di toccare qualcosa. Replication = copia di emergenza su un altro server. Usi entrambi per scopi diversi — non sono alternativi.
Implementing Secure Systems#
mindmap
root((Secure Systems))
Endpoint Security
Antivirus signature
EDR behavioral
XDR multi-layer
HIPS block attivo
Hardening
Disabilita servizi
Rimuovi software inutile
Cambia default password
Disk encryption
Config Management
Baseline sicura
Master image
Integrity measurements
Patch management
Change management
Application Control
Allow list blocca tutto
Block list consente tutto
Quarantena casi grigi
Hardware Sicurezza
TPM
FDE
Secure Boot
Remote Attestation
Endorsement Key
HSM removibile
KMS centralizzato
Boot Integrity
UEFI Secure Boot
Measured Boot
PCR hash chain
Decommissioning
Data wiping
Legacy vs EOL
Compensating controls
I sistemi sicuri devono essere sicuri sia al momento del deployment che durante tutto il ciclo di vita. In questo contesto, "sistema" = qualsiasi host: server, workstation, laptop, dispositivo di rete, mobile.
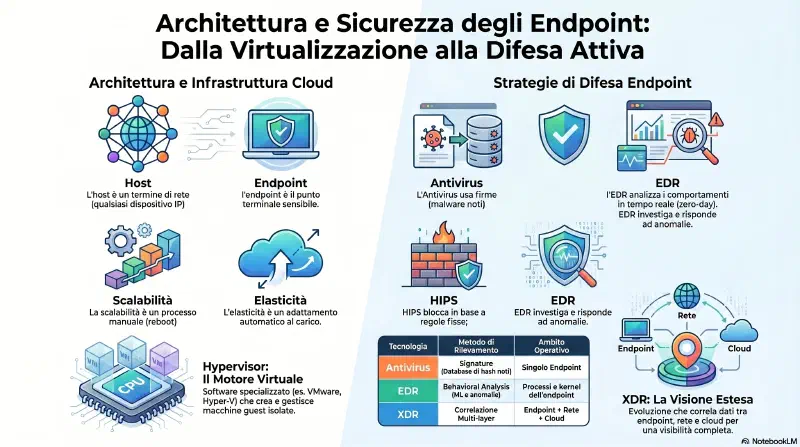
Endpoint Security Software#
Un endpoint e' il dispositivo che sta all'estremita' della rete — il punto finale dove il traffico arriva o parte. Non un router o uno switch (che spostano traffico), ma il dispositivo che lo usa: laptop, server, VM, smartphone, IoT. Il nome viene da "end point" = punto terminale della comunicazione di rete.
Gli endpoint contengono dati sensibili, accedono a risorse critiche, viaggiano e si connettono a reti diverse — sono i bersagli piu' esposti. Quattro categorie principali di protezione:
Antivirus: scansiona l'endpoint alla ricerca di virus, worm, trojan e codice malevolo noto. Opera per signature: calcola l'hash di ogni file e lo confronta con un database di hash di malware noti (le "definizioni"). Scansiona anche i byte pattern interni al file per rilevare varianti che cambiano l'hash ma mantengono il codice malevolo. Limite: un malware zero-day non ha firma nel database — passa invisibile. Per questo esiste EDR.
EDR — Endpoint Detection and Response: gira direttamente sul dispositivo e monitora in tempo reale processi, file, connessioni di rete e chiamate al kernel. Usa behavioral analysis — non cerca solo signature, ma comportamenti anomali. Esempio concreto: un PDF malevolo viene aperto. L'EDR vede che Adobe Reader sta iniettando codice in powershell.exe e aprendo una connessione verso un IP esterno — comportamento impossibile per un PDF legittimo. Blocca il processo prima del danno. Un antivirus classico non lo avrebbe rilevato: zero-day, nessuna firma disponibile.
XDR — Extended Detection and Response: evoluzione dell'EDR che va oltre il singolo endpoint. Include dispositivi di rete, infrastruttura cloud, IoT — visione completa dell'intero ambiente IT. Rileva attacchi che attraversano piu' livelli (es: compromissione endpoint → lateral movement sulla rete → esfiltrazione via cloud).
HIPS — Host Intrusion Prevention System: applica il concetto di IPS al singolo host. Usa behavior analysis, file integrity monitoring e application control per prevenire accessi non autorizzati o manomissioni. Blocca attivamente, non solo rileva.
| Tool | Dove opera | Come rileva | Risposta |
|---|---|---|---|
| Antivirus | Endpoint | Signature (noti) | Automatica |
| EDR | Endpoint | Behavioral analysis | Blocco + alert |
| XDR | Endpoint + rete + cloud | Correlazione multi-layer | Blocco + investigation |
| HIPS | Singolo host | Behavior + file integrity | Blocco attivo |
Endpoint vs EDR — ruoli distinti:
- Endpoint = il dispositivo (sostantivo) — la VM, il laptop, il server
- EDR = il software che gira sull'endpoint per monitorarlo (strumento)
Host vs Endpoint: stessa cosa, lente diversa.
- Host = termine di rete, qualsiasi dispositivo con IP (un router e' un host).
- Endpoint = termine di sicurezza, il dispositivo finale dove i dati arrivano o partono e che contiene dati sensibili. Un router non e' un endpoint. Ogni endpoint e' un host, non ogni host e' un endpoint.
HIPS vs EDR:
| HIPS | EDR | |
|---|---|---|
| Approccio | Rule-based (regole predefinite) | Behavioral analysis (ML, anomalie) |
| Focus | Prevenire accessi non autorizzati | Rilevare, investigare, rispondere |
| Risposta | Blocca in base a regole fisse | Blocca + registra + forensics |
| Tecnologia | Piu' vecchia, statica | Moderna, adattiva |
| Analogia | Firewall del singolo host | Telecamera + sistema d'allarme |
HIPS dice "questa azione e' nella lista dei vietati, blocco". EDR dice "questo comportamento e' anomalo, indago, blocco, e registro tutto per l'analisi post-incidente".
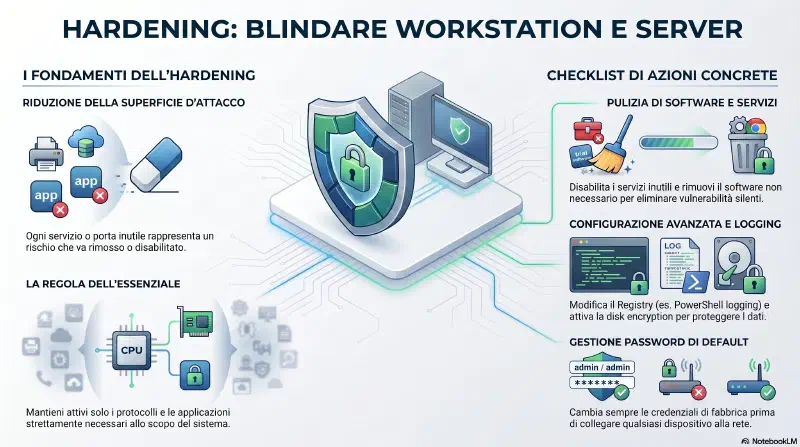
Hardening Workstations and Servers#
Hardening guides
L'installazione di default non e' mai sicura. Il primo passo e' trovare una guida di hardening per quel sistema:
- Manufacturer — il vendor pubblica spesso le proprie raccomandazioni di hardening
- Third-party — CIS (Center for Internet Security) pubblica CIS Benchmarks per centinaia di OS e applicazioni, standard di settore
- Se non esiste una guida ufficiale: community e forum tecnici
Hardening = rendere un OS o un'applicazione piu' sicuri rispetto alla configurazione di default. Ogni sistema appena installato ha servizi attivi, porte aperte, software preinstallato che non servono — ogni elemento inutile e' superficie di attacco in piu'.
Regola base: un sistema deve avere solo le applicazioni, i servizi e i protocolli necessari al suo scopo. Se FTP non serve, non gira. Se non gira, non e' attaccabile. Se una porta e' chiusa, il relativo servizio non e' raggiungibile.
Azioni concrete di hardening:
- Disabilitare servizi inutili — riduce le porte aperte e i vettori di attacco
- Rimuovere software non necessario — il software ha bug e vulnerabilita'. Se non lo usi, rimuoverlo elimina quelle vulnerabilita' senza aspettare una patch
- Modificare il Registry (Windows) — esempio tipico: il logging di PowerShell non e' attivo di default. Gli attaccanti usano PowerShell spesso proprio perche' non lascia tracce. Gli admin lo abilitano come parte dell'hardening
- Disk encryption — sempre piu' comune come parte del processo standard
- Cambiare le password di default — alcuni sistemi e dispositivi escono dalla fabbrica con password pubblicate nella documentazione del vendor. Vanno cambiate prima di connettere il sistema alla rete
Exam tip: hardening non e' solo "applicare patch". Rimuovere software non necessario elimina le vulnerabilita' invece di rattopparle. E' una difesa strutturale, non reattiva.
Hardening Network Infrastructure#
Switch, router, firewall e altri dispositivi di rete hanno caratteristiche di hardening diverse da workstation e server.
Embedded OS — non e' Windows o Linux
Questi dispositivi girano su un sistema operativo proprietario embedded, creato dal vendor specificamente per quel dispositivo. Conseguenze dirette:
- Le patch vengono solo dal manufacturer — nessun Windows Update, nessun apt. Se Cisco rilascia un aggiornamento per un router Cisco, solo Cisco ha quella patch.
- Gli aggiornamenti sono rari — il software e' stabile e purpose-built, non si aggiorna spesso.
- Proprio per questo, quando il manufacturer rilascia una patch di sicurezza per un dispositivo di rete, e' un evento importante — va valutata e applicata.
Azioni di hardening standard:
- Cambiare le credenziali di default — ogni dispositivo di rete esce dalla fabbrica con username/password documentati pubblicamente (es.
admin/admin). Vanno cambiate prima della messa in produzione. - Configurare autenticazione — locale sul dispositivo, oppure centralizzata su un authentication server (RADIUS, TACACS+)
- Verificare patch disponibili — controllare periodicamente il sito del manufacturer
Le credenziali di default sui dispositivi di rete sono una delle cause piu' comuni di breach. Un router con admin/admin raggiungibile dall'esterno e' una porta aperta.
Configuration Enforcement#
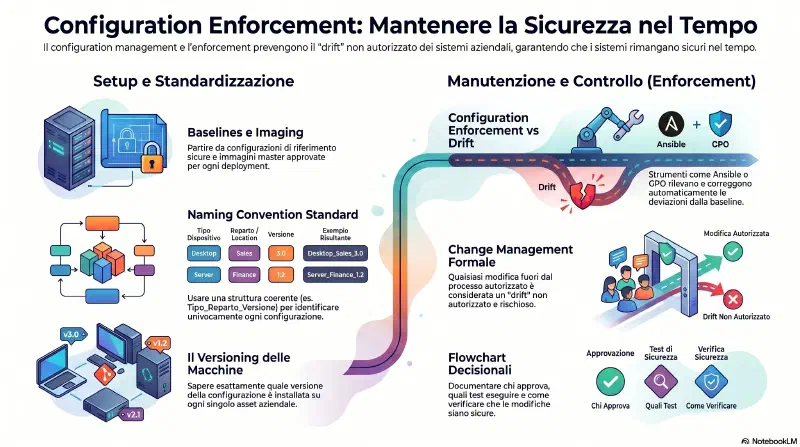
Gli amministratori usano due strumenti principali insieme al configuration management:
- Baselines — la configurazione sicura di riferimento (vedi sezione successiva)
- Imaging — deployare sistemi da un'immagine master gia' configurata e approvata
Il change management (vedi sezione dedicata) complementa il configuration management: definisce il processo formale e autorizzato per modificare una configurazione nel corso della vita del sistema. Tutto quello che cambia fuori dal processo di change management e' drift non autorizzato.
Flowchart e diagrammi: molte organizzazioni usano diagrammi per documentare i processi di configuration management. I flowchart in particolare servono a documentare il processo decisionale per modificare una configurazione — chi deve approvare, quali test fare, come verificare che la modifica non rompa nulla.
Naming convention: le grandi organizzazioni usano convenzioni di naming standard per identificare le configurazioni. La scelta dello standard specifico non e' critica — cio' che conta e' sceglierne uno e seguirlo in modo coerente. Una struttura tipica:
[tipo dispositivo]_[reparto o location]_[versione]
Desktop_Sales_3.0
→ immagine per desktop, reparto Sales, terza versione major
Server_Finance_1.2
→ immagine per server, reparto Finance, versione 1.2Con una naming convention consistente sai esattamente quale versione della configurazione standard e' installata su ogni macchina — equivale al versioning del software.
Analogia da dev: e' come avere un docker-compose.yml in repo che definisce l'ambiente esatto. Tutti devono usare quello. Se qualcuno lo modifica localmente, la CI/CD lo rileva. Configuration enforcement fa la stessa cosa sui sistemi aziendali — strumenti come Ansible, Puppet, Chef o Group Policy applicano la configurazione e rilevano le deviazioni.
Secure Baseline and Integrity Measurements#
Una baseline e' un punto di partenza noto e sicuro. E' il blueprint del sistema: come deve essere configurato, cosa deve girare, cosa non deve girare. Il concetto si applica a tre momenti distinti del ciclo di vita di un sistema:
- Establish — gli amministratori definiscono la configurazione iniziale sicura usando strumenti specifici per deployare i sistemi in modo consistente.
- Deploy — la baseline viene applicata durante il build del sistema, oppure distribuita a sistemi esistenti via Group Policy o altri configuration management tool.
- Maintain — l'organizzazione cambia, cambia il panorama delle minacce. Le baseline vanno aggiornate e ridistribuite seguendo le policy di change management.
Il beneficio principale delle secure baseline e' che migliorano la security posture complessiva dell'organizzazione. Configurazioni deboli sono uno dei problemi di sicurezza piu' comuni — le baseline lo eliminano alla radice, perche' definiscono il minimo garantito su ogni sistema.
Baseline = blueprint del sistema. Come un docker-compose.yml o un ansible playbook versionato: tutti i sistemi partono da li', e qualsiasi deviazione e' rilevabile.
Dopo il deploy, gli amministratori usano gli integrity measurements per verificare che il sistema non si sia discostato dalla baseline. Se un file di configurazione cambia, se un servizio viene abilitato fuori dal processo di change management, l'integrity check lo rileva.
Using Master Images for Baseline Configurations#
Il metodo piu' comune per deployare sistemi in modo coerente e' partire da una master image: uno snapshot di un sistema sorgente gia' configurato e testato, che viene poi distribuito su piu' macchine.
La master image e' una copia completa del sistema sorgente catturata in un momento preciso — non uno snapshot incrementale. Se si migliorano le configurazioni del sistema sorgente e si ricattura l'immagine, la maggior parte dei tool produce una nuova immagine completa. Una volta deployata, il personale non deve seguire checklist complesse: il sistema arriva gia' configurato con tutte le impostazioni di sicurezza incluse.
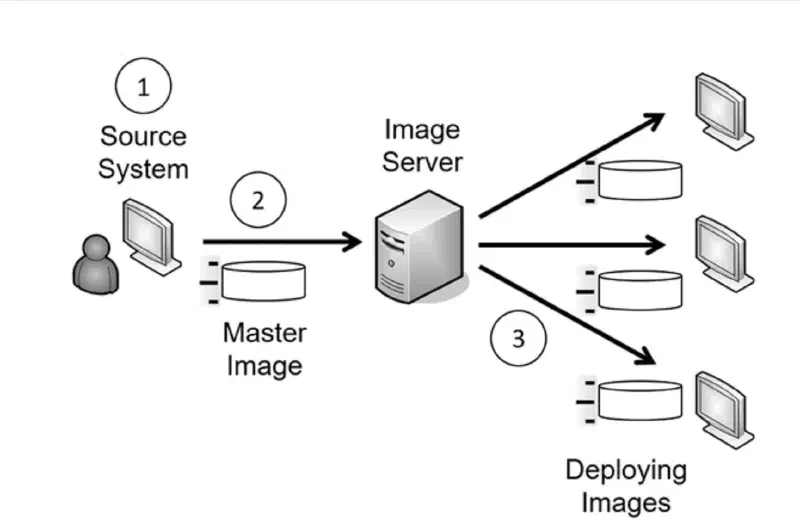
Il processo in tre passaggi:
Step 1 — Preparare il sistema sorgente Si parte da un sistema vuoto. Si installa e configura il SO, si installano le applicazioni necessarie, si applicano le impostazioni di sicurezza (hardening). Si eseguono test estensivi prima di andare al passo successivo.
Step 2 — Catturare l'immagine L'immagine catturata diventa la master image: un semplice file archiviato su un image server (server di rete dedicato alla distribuzione delle immagini) o copiato su media esterno (DVD, USB). Tool comuni: Symantec Ghost, Microsoft WDS (Windows Deployment Services), strumenti gratuiti inclusi in Windows Server.
Step 3 — Distribuire l'immagine Le macchine target si avviano dalla rete (PXE boot), si connettono all'image server e scaricano l'immagine automaticamente. Questo permette di deployare decine di macchine in parallelo senza toccarle fisicamente. Ogni macchina riceve esattamente la stessa configurazione del sistema sorgente. L'image server e' anche il punto da cui si fa rebuild di una singola macchina guasta, senza media fisici.
Il tempo investito nella preparazione scala: poche ore per un'aula, settimane o mesi per migliaia di sistemi aziendali. Ma una volta creata, il deployment e' rapido e richiede minimo sforzo amministrativo.
Due benefici principali:
| Beneficio | Dettaglio |
|---|---|
| Secure starting point | La configurazione di sicurezza e' gia' dentro l'immagine. Chi deploya non deve ricordarsi checklist o impostazioni — arriva tutto preconfigurato. Solo settings specifici (es. nome computer) vengono configurati dopo il deploy. |
| Riduzione dei costi | I sistemisti imparano un solo ambiente, non N ambienti diversi. Meno tempo a capire la configurazione, piu' tempo a risolvere il problema reale. Questo si chiama ridurre il TCO — Total Cost of Ownership. |
L'imaging non si limita ai desktop: si puo' fare su qualsiasi sistema, inclusi i server. Un'organizzazione con 50 database server puo' usare le immagini per rebuild rapidi nel disaster recovery — molto piu' veloce che ricostruire da zero. Se le immagini sono mantenute aggiornate, il server ripristinato parte gia' in uno stato sicuro.
Master image = secure starting point garantito. Gli amministratori usano integrity measurements per rilevare quando un sistema si discosta dalla baseline — ovvero quando qualcosa e' cambiato rispetto all'immagine di partenza.
Exam tip: la master image fornisce un secure starting point. Viene spesso creata con template o altri tool per costruire secure baseline. Gli integrity measurements rilevano le deviazioni dalla baseline nel tempo.
Patching and Patch Management#
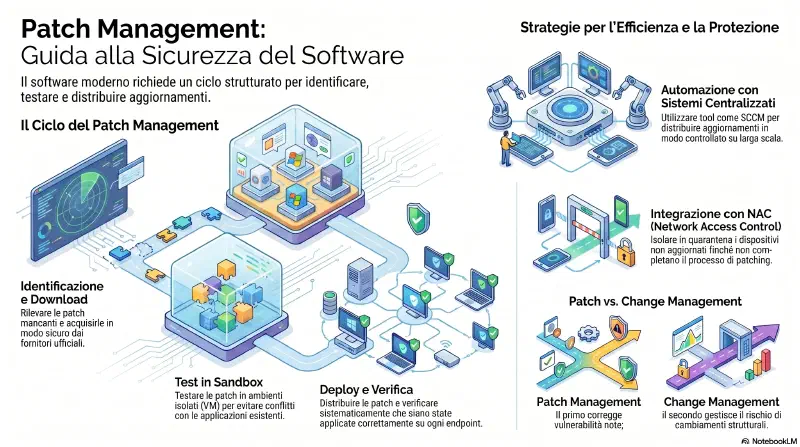
Applicare le patch e' uno dei modi piu' efficaci per ridurre le vulnerabilita': protegge da cio' che e' gia' noto e documentato. Le organizzazioni piu' piccole abilitano gli auto-update — i sistemi controllano, scaricano e applicano gli aggiornamenti autonomamente.
Il patch management e' la gestione strutturata di questo processo. Non e' solo "applicare patch" — e' un ciclo completo:
Identify → Download → Test → Deploy → VerifyTest in sandbox: prima di distribuire una patch in produzione, gli amministratori la testano in un ambiente isolato, tipicamente una VM. Una patch puo' rompere un'applicazione o causare conflitti — meglio scoprirlo in sandbox.
Deploy automatizzato: le patch non si applicano a mano macchina per macchina. Si usano tool di systems management come Microsoft Configuration Manager (SCCM) che esaminano gli endpoint, determinano quali patch mancano e le distribuiscono in modo controllato.
Verifica sistematica: dopo il deploy, gli stessi tool interrogano periodicamente i sistemi e recuperano la lista delle patch installate. La confrontano con la lista di quelle attese e generano report sulle discrepanze. L'amministratore sa esattamente quali macchine sono aggiornate e quali no.
Integrazione con NAC: in alcune reti gli amministratori combinano il patch management con tecnologie NAC (Network Access Control). I sistemi non patchati vengono isolati in una rete di quarantena finche' non si aggiornano. La macchina non patchata non accede alla rete principale — incentivo forte a restare aggiornati.
Un patch management debole o assente lascia vulnerabilita' prevenibili aperte agli attaccanti: nel SO, nelle applicazioni, nel firmware.
Patch management = identificare, scaricare, testare, deployare, verificare. Il ciclo completo. Non basta applicare — bisogna verificare che sia stato applicato ovunque.
Exam tip: patch management protegge dalle vulnerabilita' note. Il change management definisce il processo e la struttura contabile per gestire modifiche e aggiornamenti — obiettivo: ridurre i rischi di outage inattesi e documentare ogni cambiamento. Sono complementari, non la stessa cosa.
Change Management#
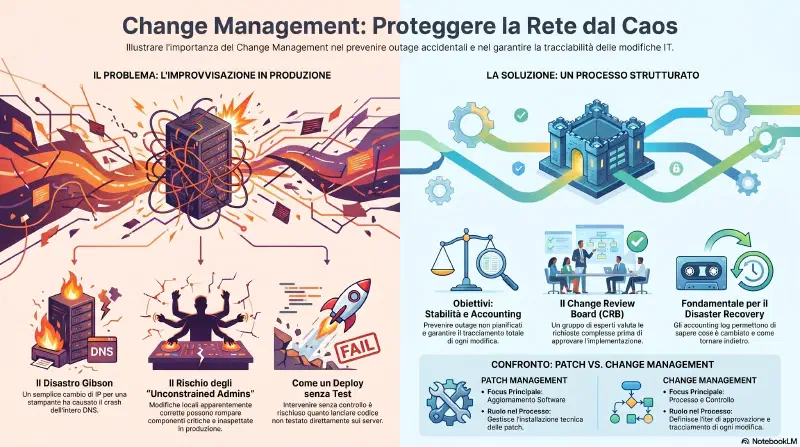
Esempio Gibson: un admin risolve un problema di stampante cambiandone l'IP. Funziona. Ma il nuovo IP era gia' assegnato a un server DNS — conflitto di indirizzi, il DNS smette di rispondere, tutta la rete va giu'. Nessuno sa cosa e' successo finche' un altro admin non trova il problema per caso.
E' esattamente come fare un deploy di codice senza test: la modifica sembra giusta localmente, ma rompe qualcosa di inatteso in produzione. Il change management e' il processo formale che evita questi disastri.
Il change management definisce il processo per qualsiasi tipo di modifica o aggiornamento ai sistemi IT — configurazioni, applicazioni, patch, dispositivi di rete. Ha due obiettivi:
- Evitare outage non pianificati o failure di sicurezza causati da modifiche mal gestite
- Fornire una accounting structure — un sistema di tracciamento e documentazione per ogni cambiamento
Con un processo di change management attivo, gli amministratori non fanno modifiche appena identificano un'esigenza. Passano prima dalla richiesta formale, che viene esaminata e approvata. Il processo:
- Modifiche semplici vengono approvate rapidamente
- Richieste piu' complesse vengono esaminate da un change review board (gruppo di esperti di aree diverse) che puo' approvare, modificare o rifiutare
- I sistemi di change management automatizzati creano accounting log per ogni richiesta: dall'apertura all'implementazione, tutto e' tracciato
Questa documentazione e' fondamentale per il disaster recovery: se un sistema modificato smette di funzionare, il change management dice esattamente cosa e' cambiato e come tornare allo stato precedente.
Il change management non vale solo per i server. Si applica a qualsiasi dispositivo sulla rete: firewall, proxy, sistemi DLP, MDM, router, switch.
Exam tip: patch management e change management sono complementari. Il patch management gestisce gli aggiornamenti del software. Il change management definisce il processo e l'accounting structure per qualsiasi modifica — incluse le patch. Una patch che bypassa il change management e' un rischio, anche se tecnicamente corretta.
Application Allow and Block Lists#
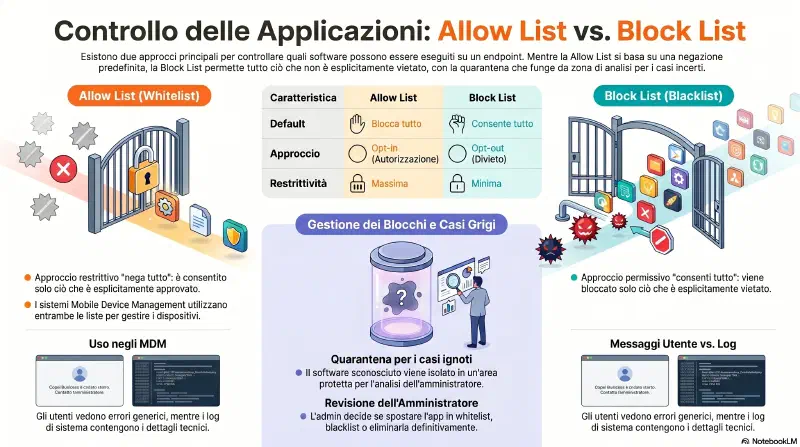
Allow list (whitelist): lista delle applicazioni autorizzate. Tutto cio' che non e' in lista viene bloccato, senza eccezioni. E' la modalita' piu' restrittiva: il default e' "nega tutto, permetti solo cio' che ho approvato esplicitamente".
Block list (blacklist / deny list): lista delle applicazioni vietate. Tutto il resto e' consentito. Molto piu' permissiva: il default e' "consenti tutto, blocca solo cio' che ho vietato esplicitamente".
| Allow list | Block list | |
|---|---|---|
| Default | Blocca tutto | Consente tutto |
| Approccio | Opt-in (autorizzazione esplicita) | Opt-out (divieto esplicito) |
| Restrittivita' | Massima | Minima |
| Esempio d'uso | Workstation aziendali (solo sw approvato) | Bloccare un gioco specifico |
| App sconosciuta (es. Photoshop non in lista) | Bloccata — non e' nell'elenco approvati | Permessa — non e' nell'elenco vietati |
La logica e' inversa: la block list parte dal "si'" e aggiunge i "no". La allow list parte dal "no" e aggiunge i "si'". Un malware sconosciuto passa sempre con la block list (non lo conosce). Viene bloccato sempre con la allow list (non e' negli approvati).
Punto critico — dove agiscono: allow list e block list controllano l'esecuzione, non l'installazione. Il malware puo' essere copiato sul disco (via USB, email, download) senza che nessuna lista lo intercetti. Il blocco scatta nel momento in cui qualcosa tenta di avviarlo. L'antivirus scansiona i file cercando firme note. L'allow list blocca l'esecuzione di qualsiasi cosa non sia approvata — firma nota o meno. Contro malware sconosciuto: AV fallisce, allow list tiene.
Le applicazioni MDM (Mobile Device Management) usano entrambe per gestire le app sui dispositivi mobili.
Cosa vede l'utente quando viene bloccato: i messaggi sono spesso criptici — un errore di permessi o un fallimento generico. I log dell'applicazione contengono invece i dettagli esatti del blocco.
Quarantena: alcuni sistemi supportano la quarantena per le app che non rispettano le liste. Se un utente tenta di installare un'app non presente nella allow list (ne' nella blacklist, ne' nella whitelist — semplicemente sconosciuta), il sistema la mette in un'area protetta. L'app non gira, ma viene conservata perche' gli amministratori possano esaminarla e decidere: aggiungerla alla whitelist, alla blacklist, o eliminarla. E' il meccanismo per gestire i casi grigi senza perdere le prove.
Exam tip: allow list = blocca tutto tranne la lista. Block list = consente tutto tranne la lista. La quarantena e' per i casi grigi — l'app non gira ma non viene eliminata, cosi' l'admin puo' analizzarla.
Disk Encryption#
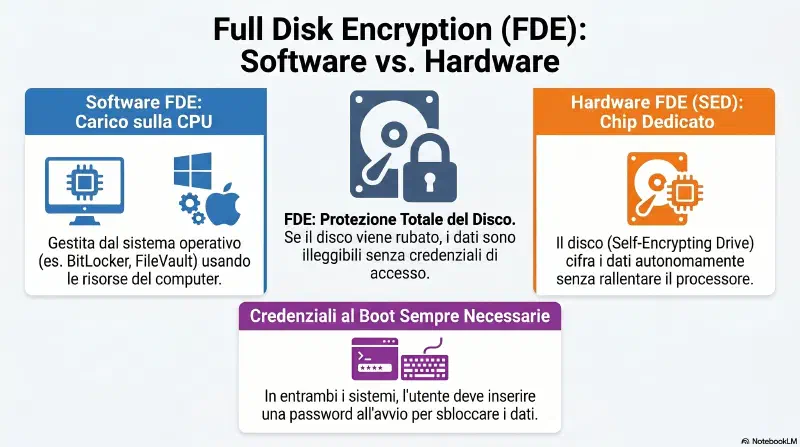
Due approcci:
Software FDE: la cifratura e' gestita dal sistema operativo o da un'applicazione. Il SO intercetta ogni operazione di lettura/scrittura e cifra/decifra i dati in tempo reale usando la CPU.
- BitLocker (Windows) — integrato in Windows Pro/Enterprise
- FileVault (macOS) — integrato in macOS
- VeraCrypt (open source) — cifra partizioni o interi dispositivi, cross-platform
Hardware FDE — SED (Self-Encrypting Drive): la circuiteria di encryption e' integrata direttamente nel drive. Non e' il SO a fare il lavoro — e' il disco stesso con il proprio chip dedicato.
Il flusso SED:
- Al setup dell'unita', l'utente inserisce le credenziali
- Ad ogni avvio del sistema, reinserisce le credenziali
- Il drive le verifica e decifra — tutto nella sua circuiteria, senza coinvolgere la CPU del sistema
L'"automatico" del SED si riferisce al fatto che la cifratura/decifratura avviene nel firmware del disco senza software aggiuntivo — non che non servano credenziali. Le credenziali al boot sono comunque richieste.
| Software FDE | Hardware FDE (SED) | |
|---|---|---|
| Chi cifra/decifra | SO / CPU | Circuiteria del drive |
| Dove avviene | In software | Nel firmware del disco |
| Credenziali al boot | Si | Si |
| Impatto performance | Minimo (CPU moderna) | Nessuno (hardware dedicato) |
| Esempi | BitLocker, FileVault, VeraCrypt | SED di Samsung, Seagate, WD |
Exam tip: FDE protegge tutto il contenuto del disco. Puo' essere implementata via software (BitLocker, FileVault) o via hardware con un SED. In entrambi i casi le credenziali al boot sono necessarie — la differenza e' dove avviene il lavoro crittografico.
FDE enterprise — due considerazioni critiche per il planning:
TPM presence: in un rollout enterprise, FDE usa il TPM per conservare la chiave di cifratura e sbloccare il disco al boot automaticamente — senza che l'utente inserisca una password ogni volta. Senza TPM, FDE o non funziona, o richiede un PIN manuale ad ogni avvio (impraticabile su larga scala).
Key escrow: copia della chiave di recovery conservata in modo sicuro fuori dal device (es. Active Directory, server centralizzato). Se il dipendente dimentica il PIN, il TPM si guasta, o il device viene consegnato a un nuovo proprietario, la chiave di escrow permette di recuperare i dati. Senza key escrow, un laptop cifrato con TPM guasto diventa un mattone — dati irrecuperabili. Exam tip: "select two" su FDE planning → TPM presence + key escrow.
Boot Integrity#
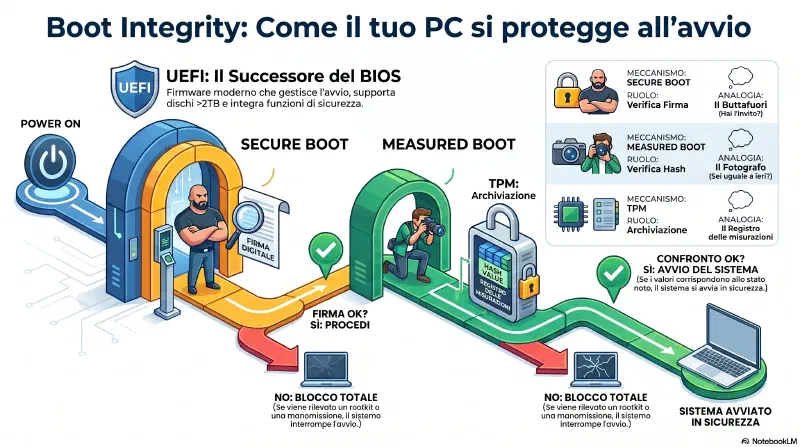
Tre concetti distinti con ruoli diversi:
┌─────────────────────────────────────────────────────┐
│ BOOT INTEGRITY (obiettivo) │
│ "il sistema deve avviarsi integro o non partire" │
└─────────────────────────────────────────────────────┘
|
┌──────────────┴──────────────┐
▼ ▼
┌──────────────────┐ ┌─────────────────────┐
│ SECURE BOOT │ │ MEASURED BOOT │
│ (meccanismo) │ │ (processo) │
│ │ │ │
│ "questo file │ │ "questo file │
│ e' firmato da │ │ ha lo stesso hash │
│ qualcuno di │ │ di ieri?" │
│ fidato?" │ │ │
│ │ │ → registra nel TPM │
│ SI/NO binario │ │ → confronta valori │
│ UEFI fa il gate │ │ → blocca se diverso │
└──────────────────┘ └─────────────────────┘In ordine al boot:
1. POWER ON
|
2. UEFI si avvia
|
3. SECURE BOOT → controlla firma del bootloader
| firma ok? → avanti
| firma mancante/errata? → BLOCCO
|
| [BOOTLOADER: piccolo programma sul disco, sa dove sta il kernel.
| Si carica prima di tutto — rootkit qui = invisibile all'antivirus.
| Esempi: GRUB (Linux), Windows Boot Manager]
|
4. MEASURED BOOT → calcola hash del bootloader, lo salva nel TPM
|
5. SECURE BOOT → controlla firma del kernel
|
6. MEASURED BOOT → calcola hash del kernel, salva nel TPM
|
7. fine boot → i valori nel TPM fotografano lo stato del sistema
| se domani qualcosa cambia → anomalia rilevata
▼
Sistema avviato ✓- Secure Boot = il buttafuori — "hai l'invito (firma)? No → fuori"
- Measured Boot = il fotografo — "sei uguale a ieri? No → allarme"
Cos'e' il bootloader
Il bootloader e' il primo programma che UEFI carica dopo aver trovato il disco di avvio. Il suo unico compito e' caricare il kernel del SO in memoria e passargli il controllo. E' uno strato intermedio necessario perche' il firmware non sa leggere il filesystem del disco — non conosce ext4 o NTFS. Il bootloader si.
UEFI
|
└─→ BOOTLOADER ← piccolo programma sul disco (settore di avvio)
| sa dove trovare il kernel
└─→ KERNEL OS ← il vero sistema operativo
|
└─→ tutto il resto (driver, servizi, desktop...)Esempi: GRUB (Linux — il menu che appare nel dual boot), Windows Boot Manager (Windows).
E' il componente piu' interessante da attaccare: un rootkit nel bootloader si carica prima del kernel, prima dell'antivirus, prima di tutto. Per questo Secure Boot lo verifica per primo.
Boot Security e UEFI
Il BIOS (Basic Input/Output System) e' il firmware che da' a un computer le istruzioni base per avviarsi. E' sia hardware che software: un chip fisico sulla scheda madre, che contiene firmware inciso in memoria non volatile. Al boot esegue controlli iniziali (POST), trova il disco di avvio e passa il controllo al bootloader.
I sistemi moderni usano UEFI (Unified Extensible Firmware Interface) al posto del BIOS. UEFI fa le stesse cose ma aggiunge funzionalita' importanti:
- Supporta dischi oltre i 2TB
- E' progettato per essere indipendente dalla CPU
- Include Secure Boot: verifica che ogni componente del processo di avvio sia firmato crittograficamente da un'autorita' fidata — blocca i rootkit prima che possano caricarsi
La gerarchia e' questa:
UEFI ← il meccanismo (hardware/firmware)
└─ Secure Boot ← funzionalita' di verifica firma
└─ Measured Boot ← processo che misura ogni stadio e blocca se non integroFlashing: sia BIOS che UEFI possono essere aggiornati tramite flashing. Il termine viene da "flash memory" — il tipo di chip usato per conservare il firmware. Il flashing sovrascrive il firmware esistente con una versione nuova. E' rischioso: se il processo si interrompe a meta' (blackout, crash), il chip contiene codice corrotto e il sistema non sa piu' come avviarsi — stato chiamato "bricked" (mattone). Per questo i produttori spesso includono meccanismi di recovery o dual-chip.
Exam tip: measured boot e' il processo che verifica l'integrita' a ogni stadio. UEFI Secure Boot e' il meccanismo che lo rende possibile verificando le firme crittografiche. Se il sistema perde integrita', non si avvia — e' una difesa, non un bug.
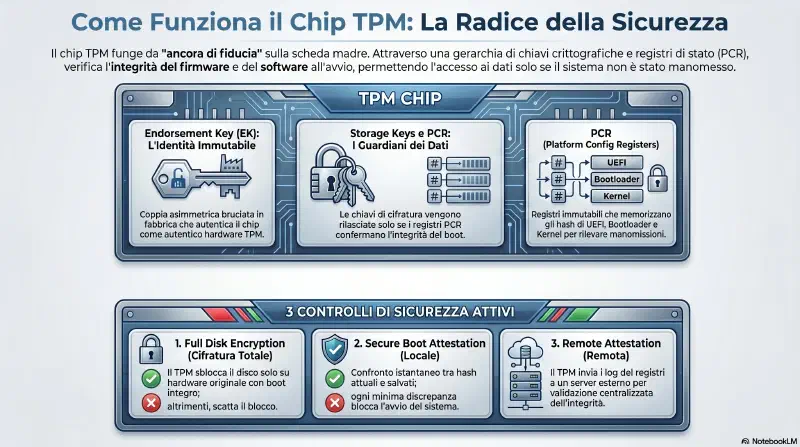
TPM — Trusted Platform Module#

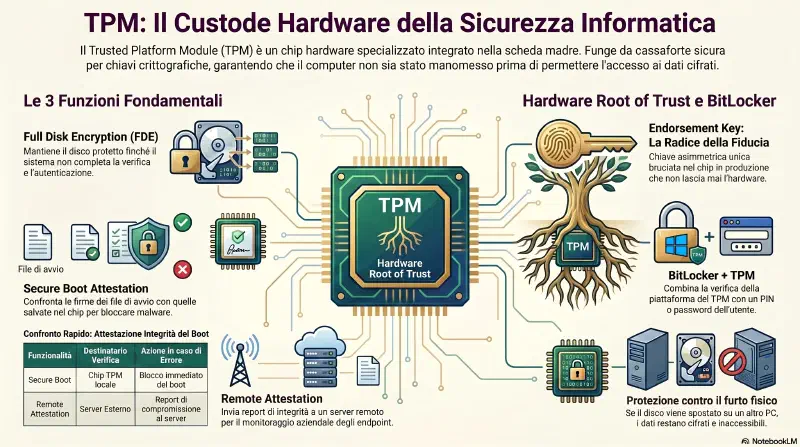
Caratteristiche chiave:
- Persistent memory: le chiavi generate vengono conservate nel chip in modo permanente e sono uniche per quella macchina
- Password protected: l'accesso alle informazioni nel TPM e' protetto da password
- Immune a brute force e dictionary attack: non e' possibile iterare tentativi di accesso per forzare il TPM — il chip blocca questo tipo di attacco per design
Una volta abilitato, il TPM fornisce tre funzionalita' principali:
ENDORSEMENT = attestare ufficialmente che e' valido
TPM / HSM
│
├─ genera ──────────► ENDORSEMENT KEY
│ │
│ │ (OTP — bruciata in fabbrica,
│ │ non esce mai dal chip)
│ │
│ └──► autentica il chip stesso
│ "sono un TPM autentico"
| Genuine Check ✅
│
├─ genera ──────────► STORAGE KEYS
│ │
│ │ (create internamente,
│ │ non escono mai dal chip)
│ │
│ └──► cifrano il disco
│ rilasciate SOLO se boot è integro
│
└─ misura ──────────► PCR (hash di ogni componente boot)
│
├──► SECURE BOOT ATTESTATION
│ │
│ └── confronta hash localmente
│ uguale → boot OK
│ diverso → BLOCCO
│
└──► REMOTE ATTESTATION
│
└── invia hash a server remoto
server verifica
OK → boot
KO → blocco1. Full Disk Encryption Il TPM mantiene il disco cifrato e protetto finche' il sistema non completa verifica e autenticazione. Se provi ad accedere al disco senza passare dal TPM — ad esempio spostando il disco su un altro PC — il disco resta cifrato perche' il TPM non e' disponibile.
2. Secure Boot Attestation Quando viene configurato, il TPM cattura le firme (hash) dei file chiave usati per il boot e le conserva al proprio interno. Ad ogni avvio, il processo di secure boot confronta i file attuali con le firme salvate. Se rileva modifiche — ad esempio da malware — blocca il boot per proteggere i dati sul disco.
3. Remote Attestation Funziona come il secure boot, ma invece di confrontare localmente invia il report a un sistema remoto. Il TPM cattura le firme dei file di boot e le manda a un server esterno. Ad ogni avvio, il sistema invia un report aggiornato al server remoto, che verifica e attesta che il sistema e' integro. Usato in ambienti aziendali dove un server centrale monitora l'integrita' di tutti gli endpoint.
SECURE BOOT ATTESTATION REMOTE ATTESTATION
(verifica locale) (verifica remota)
TPM → confronta hash TPM → invia hash
con copia interna a server remoto
| |
OK → boot server verifica
NO → blocco OK → boot / NO → bloccoCome misura: PCR e hash
Il TPM usa SHA-256 (o SHA-1 sui sistemi piu' vecchi) per calcolare il digest di ogni file critico del boot. I digest vengono conservati nei PCR (Platform Configuration Registers) — registri interni dedicati, uno per ogni componente misurato. I PCR non si possono sovrascrivere dall'esterno: si estendono solo in avanti (ogni nuova misurazione si concatena alla precedente) e si azzerano solo con un riavvio fisico.
Due esempi concreti di file misurati:
Windows:
C:\Windows\System32\bootmgr ← bootloader
C:\Windows\System32\winload.efi ← carica il kernel
Linux:
/boot/grub/grubx64.efi ← GRUB bootloader
/boot/vmlinuz-6.x.x-generic ← kernel LinuxSe un byte di uno di questi file cambia — rootkit, manomissione, corruzione — il digest e' diverso da quello nel PCR. Boot bloccato.
Endorsement Key — hardware root of trust#
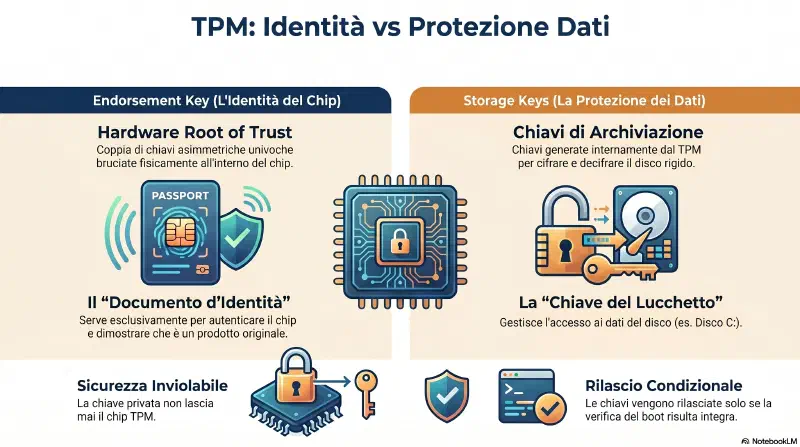
L'endorsement key non cifra il disco — serve per autenticare il TPM stesso: dimostra che il chip e' autentico e prodotto da un vendor fidato. Le chiavi per cifrare il disco sono separate: il TPM le genera internamente (storage keys) e le conserva al proprio interno. Le rilascia solo se la verifica del boot va a buon fine.
Endorsement Key
└─→ "sono un TPM autentico, prodotto da X"
usata per autenticare il chip stesso
Storage Keys (generate dal TPM)
└─→ "questa e' la chiave per il disco C:"
usata per cifrare/decifrare il disco
rilasciata solo se il boot e' integroStesso chip, scopi diversi: endorsement key = documento d'identita' del TPM. Storage key = chiave del lucchetto del disco.
Perche' conta: il problema della fiducia software
Bruciata = scritta in memoria non riscrivibile durante la produzione del chip in fabbrica.
Il processo fisico: durante la produzione del chip TPM, il produttore genera una coppia di chiavi asimmetrica unica e la scrive in un tipo di memoria chiamata OTP — One-Time Programmable. Come suggerisce il nome, quella memoria si può scrivere una sola volta. Dopo, è permanente — non si può cancellare, sovrascrivere, o rileggere dall'esterno.
Il problema fondamentale della sicurezza software e' questo: qualsiasi cosa vive su disco puo' essere modificata. Un certificato e' un file. Una chiave e' un file. Un file di configurazione e' un file. Se un attaccante ha accesso sufficientemente basso al sistema, puo' toccarli tutti.
La domanda diventa: da dove parte la fiducia? Su cosa puoi appoggiarti che per definizione non puo' essere manomesso via software?
La risposta e' l'hardware fisico. L'endorsement key e' scritta in memoria OTP — One-Time Programmable — durante la produzione del chip. Quella memoria si scrive una sola volta, poi e' permanente. Non si puo' cancellare, sovrascrivere, o rileggere dall'esterno. Nessun software puo' leggerla. Nessun aggiornamento firmware puo' cambiarla. Nemmeno il produttore puo' recuperarla.
Fiducia software: Fiducia hardware:
"questo certificato "questa chiave e' nel
dice che sono legittimo" silicio del chip —
| non puo' mentire"
v
puo' essere falsificato |
puo' essere sostituito v
puo' essere corrotto immutabile per designQuesto e' il significato preciso di hardware root of trust: la catena di fiducia parte da qualcosa di fisicamente immutabile, non da un file o un certificato che vive su disco. La crittografia e' matematicamente solida, ma opera su dati — se quei dati (le chiavi) possono essere rubati o sostituiti, la matematica non ti salva. L'hardware root of trust sposta il problema da "proteggere un file" a "proteggere un oggetto fisico", che per un attaccante remoto e' un problema irrisolvibile.
Il concetto si ritrova ovunque in security:
- TPM endorsement key — la catena parte dal chip fisico sulla scheda madre
- UEFI Secure Boot — ogni componente del boot verifica il successivo, ma la radice e' il firmware nel chip
- Certificati root CA — alla fine della catena c'e' un HSM fisico in una stanza blindata, con la chiave root scritta nell'hardware
┌──────────────────────────────────────────────────────────────────┐
│ TPM CHIP (scheda madre) │
│ │
│ ┌──────────────────────────────────────────────────────────┐ │
│ │ ENDORSEMENT KEY │ │
│ │ (bruciata in fabbrica — non esce mai) │ │
│ │ │ │
│ │ coppia asimmetrica pubblica + privata │ │
│ │ scopo: autenticare il TPM stesso come chip reale │ │
│ │ NON cifra il disco — è il documento d'identità del chip│ │
│ └──────────────────────────┬───────────────────────────────┘ │
│ │ "sono un TPM autentico" │
│ ▼ │
│ ┌──────────────────────────────────────────────────────────┐ │
│ │ STORAGE KEYS │ │
│ │ (generate internamente dal TPM) │ │
│ │ │ │
│ │ queste cifrano il disco │ │
│ │ vengono rilasciate SOLO se il boot è integro │ │
│ └──────────────────────────┬───────────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌──────────────────────────────────────────────────────────┐ │
│ │ PCR — Platform Config Registers │ │
│ │ │ │
│ │ PCR[0] → hash UEFI firmware │ │
│ │ PCR[4] → hash bootloader (grub / winload.efi) │ │
│ │ PCR[8] → hash kernel │ │
│ │ │ │
│ │ solo append · reset solo al riavvio fisico │ │
│ │ nessuno può sovrascriverli dall'esterno │ │
│ └──────────────────────────┬───────────────────────────────┘ │
│ │ │
└──────────────────────────────│───────────────────────────────────┘
│
▼
┌────────────────────────────────────────────┐
│ 3 CONTROLLI ATTIVI │
├────────────────────────────────────────────┤
│ │
│ 1. FULL DISK ENCRYPTION │
│ TPM verifica boot → rilascia storage key│
│ disco su altro PC → TPM assente → LOCK │
│ │
│ 2. SECURE BOOT ATTESTATION (locale) │
│ confronta hash PCR attuali vs salvati │
│ hash diverso → manomissione → BLOCCO │
│ │
│ 3. REMOTE ATTESTATION │
│ TPM invia PCR a server remoto │
│ server verifica → OK boot / KO blocco │
│ │
└────────────────────────────────────────────┘
BitLocker + TPM in pratica BitLocker usa il TPM per rilevare manomissioni di file o processi critici del SO (platform verification). L'utente fornisce poi un secondo fattore: smart card, password, o PIN. Il disco resta cifrato finche' entrambi i processi non completano — verifica piattaforma + autenticazione utente.
Scenari di protezione:
- Furto del laptop — il ladro non ha le credenziali, non accede al disco
- Modifica del SO per bypassare i controlli — il TPM rileva la manomissione, mantiene il disco cifrato
- Disco spostato su un altro PC — il TPM non e' disponibile, il disco resta cifrato
Endorsement key = chiave asimmetrica unica bruciata nel chip TPM al momento della produzione. Fornisce l'hardware root of trust. E' il termine esatto da ricordare per l'esame.
Exam tip: TPM = chip hardware con tre funzioni chiave: full disk encryption, secure boot attestation, remote attestation. L'endorsement key e' il suo hardware root of trust.
Exam trap — TPM vs BIOS per la protezione delle chiavi: Se la domanda chiede come proteggere le chiavi di cifratura del disco anche se l'OS e' compromesso, la risposta e' sempre TPM — non BIOS, non file nascosto, non USB. Il BIOS puo' essere modificato da software con privilegi sufficienti — non e' tamper-resistant. Il TPM e' un chip hardware dedicato con memoria OTP: le chiavi non escono mai dal chip e vengono rilasciate solo se il boot supera la verifica di integrita'. BIOS storage = insicuro per design. TPM = l'unica opzione che protegge anche da un OS compromesso.
HSM — Hardware Security Module#
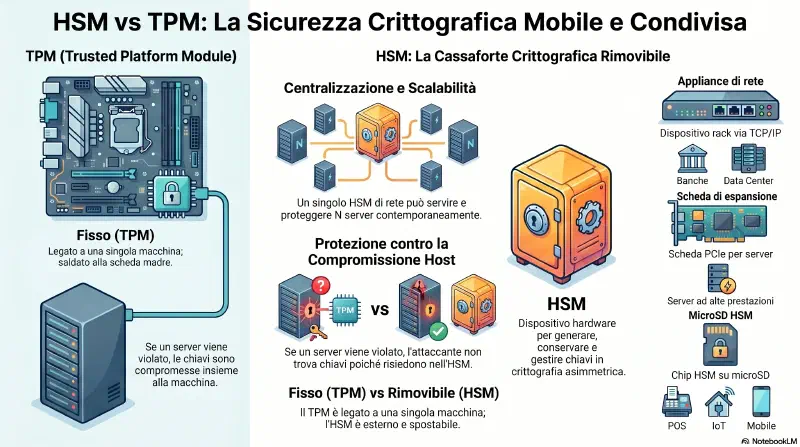
Un HSM e' un dispositivo hardware dedicato alla generazione, conservazione e gestione sicura di chiavi crittografiche. Supporta le stesse funzionalita' del TPM (hardware root of trust, secure boot, remote attestation), ma con una differenza fondamentale: e' rimovibile e condivisibile.
In ambienti grandi gli HSM sono in cluster con ridondanza: piu' unita' attive insieme, con alimentatori ridondanti e connettivita' di rete ridondante, per garantire disponibilita' continua. Se un HSM si guasta, il cluster continua a funzionare.
Cryptographic accelerator: hardware aggiuntivo (scheda plug-in o modulo separato) connesso all'HSM, progettato specificamente per eseguire operazioni crittografiche ad altissima velocita'. Necessario quando l'HSM deve cifrare e decifrare in real-time in ambienti di calcolo ad alta scala — migliaia di richieste TLS al secondo, ad esempio.
Quattro form factor:
| Form factor | Descrizione | Caso d'uso tipico |
|---|---|---|
| Network appliance | Dispositivo rack connesso via TCP/IP | Banche, CA enterprise, data center |
| Expansion card | Scheda PCIe installata nel server | Server ad alte prestazioni |
| USB HSM | Chiavetta USB con chip crittografico dedicato | Sviluppatori, firma codice, PKI small team |
| MicroSD HSM | Chip HSM su microSD (15x11x1 mm) | POS, dispositivi mobili, IoT |
Esempi USB reali: YubiHSM 2 (Yubico), Thales SafeNet eToken, Nitrokey HSM.
Differenza operativa rispetto al TPM
Il TPM e' saldato sulla scheda madre — e' legato a quella macchina. L'HSM si aggiunge, si sposta, si condivide tra piu' sistemi.
TPM HSM
──────────────────── ────────────────────────────────
saldato su scheda madre rimovibile o esterno
1 macchina = 1 TPM N server → 1 HSM di rete
non condivisibile condivisibile
key legate all'host key portabili con il dispositivoEsempio concreto — banca con 50 server web
Senza HSM ogni server gestisce le sue chiavi TLS localmente: se uno viene compromesso, quella chiave e' esposta. Con un HSM di rete:
- tutti i server fanno le operazioni crittografiche chiamando l'HSM via rete
- la chiave privata della CA non tocca mai i server — vive solo nell'HSM
- se un server viene compromesso, l'attaccante non trova nessuna chiave
- se serve spostare l'infrastruttura, scollego l'HSM e lo riattacco altrove
MicroSD HSM: stesso principio in formato microSD. Un POS o tablet critico ci inserisce una microSD HSM — il chip crittografico viaggia col dispositivo, indipendente dall'hardware del sistema ospite.
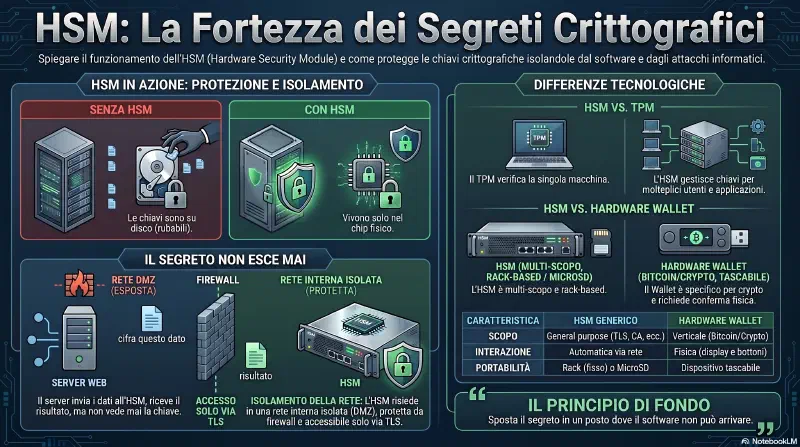
HSM — a cosa lo attacchi fisicamente?
Qui c'è la confusione: il TPM fa il genuine check e decifra il disco per quella macchina. L'HSM non sostituisce il TPM sulla singola macchina — serve per applicazioni che devono gestire chiavi per conto di molte macchine o molti utenti.
Esempio concreto: un server web HTTPS ha una chiave privata TLS. Senza HSM quella chiave sta su disco — se il server viene compromesso, l'attaccante la ruba. Con HSM:
Server web HSM (in rack, rete interna)
│ │
│── "cifra questo dato" ──────►│
│ │ operazione dentro il chip
│◄─────── "ecco il risultato" ─│
│ │
│ la chiave privata │
│ non ha mai lasciato ───────┘
│ l'HSMIl server non vede mai la chiave — manda dati, riceve risultati.
- Chiamata via rete — non è pericoloso?
L'intuizione dell'air-gap è corretta, ed è esattamente come funziona: l'HSM è su una rete interna isolata, non esposta a internet.
Internet
│
[Firewall]
│
Rete DMZ ── server web (riceve richieste HTTPS)
│
[Firewall interno]
│
Rete interna isolata ── HSM ← raggiungibile SOLO dai server autorizzatiLa comunicazione server→HSM avviene su un canale TLS mutuamente autenticato, dentro la rete interna. L'HSM stesso ha protezione fisica: se qualcuno tenta di aprirlo fisicamente, cancella le chiavi autonomamente (tamper-evident/tamper-resistant). Alcuni ambienti ad altissima sicurezza (es. root CA di grandi CA) usano HSM fisicamente air-gapped con operazioni autorizzate via smart card in cerimonie fisiche documentate.
HSM vs Hardware Wallet BTC
HSM generico Hardware wallet
──────────────────────────── ────────────────────────────
genera chiavi asimmetriche → genera chiave privata BTC
chiave non esce mai dal chip → private key non esce mai
firma operazioni internamente → firma la transazione dentro
rimovibile e portabile → rimovibile e portabile
uso generale (TLS, CA, ecc.) → solo crypto (ECDSA/secp256k1)La differenza principale è che un HSM è general-purpose — gestisce qualsiasi algoritmo, qualsiasi tipo di chiave, per qualsiasi applicazione. Un hardware wallet è verticale su un dominio specifico.
L'aggiunta che i wallet hanno rispetto a un HSM classico è il display + bottoni fisici: prima di firmare una transazione devi confermarla fisicamente sul dispositivo. Questo blocca un attacco in cui il PC host è compromesso e tenta di far firmare al wallet una transazione diversa da quella che l'utente crede di stare approvando. Un HSM in rack non ha questo problema perché non lo usa un utente finale — lo usa un'applicazione server in un ambiente controllato.
il principio di fondo è sempre lo stesso — sposta il segreto in un posto dove il software non può arrivare — e poi vedi quella stessa idea replicata a scale diverse: il chip sulla scheda madre, il rack in banca, il wallet in tasca
HSM = dispositivo rimovibile o esterno per generare, conservare e gestire chiavi in crittografia asimmetrica. Molte applicazioni server-based usano un HSM per proteggere le chiavi. Un microSD HSM e' un HSM installato su microSD, compatibile con qualsiasi slot microSD o SD.
Exam tip: la differenza TPM vs HSM e' una sola parola — rimovibile. TPM e' embedded sulla scheda madre. HSM e' esterno o removibile. Entrambi forniscono hardware root of trust, secure boot e remote attestation.
Key Management System (KMS)#
TPM gestisce le chiavi di una macchina. HSM gestisce le chiavi di un data center. Ma chi gestisce l'insieme di tutti i tipi di chiavi — TLS, SSH, BitLocker, certificati utente — distribuite su centinaia di sistemi? Un Key Management System.
Un KMS e' una console centralizzata che gestisce tutti i tipi di chiavi crittografiche dell'organizzazione da un unico punto. Puo' girare on-premises o in cloud.
Cosa gestisce:
| Tipo chiave | Esempio d'uso |
|---|---|
| SSL/TLS | Certificati dei web server HTTPS |
| SSH | Accesso remoto ai server |
| Active Directory | Autenticazione utenti Windows |
| BitLocker | Full-disk encryption degli endpoint |
Funzioni principali:
- Associa ogni chiave a utenti o sistemi specifici
- Automatic key rotation — ruota le chiavi automaticamente nel tempo
- Logging e reporting di tutte le operazioni (chi ha usato quale chiave, quando)
- Tiene le chiavi separate dai dati che proteggono — principio fondamentale
Questo ultimo punto e' critico: se le chiavi vivono sullo stesso sistema dei dati cifrati, un attaccante che compromette il sistema ottiene entrambi. Il KMS separa fisicamente i segreti dai dati.
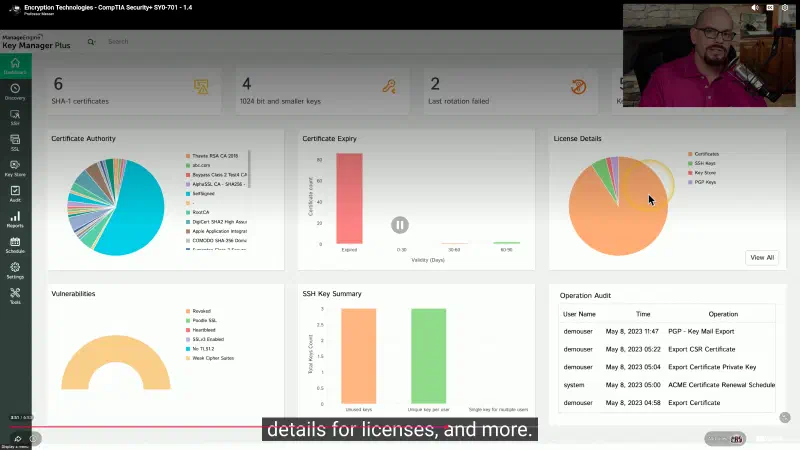
La dashboard mostra: numero di certificati SHA-1 (da migrare), chiavi deboli a 1024 bit, rotazioni fallite, scadenze imminenti, SSH key summary e audit log delle operazioni con timestamp.
Exam tip: KMS = gestione centralizzata di tutte le chiavi. Il principio chiave (letteralmente): keys must be separate from the data they protect.
Decommissioning and Disposal#
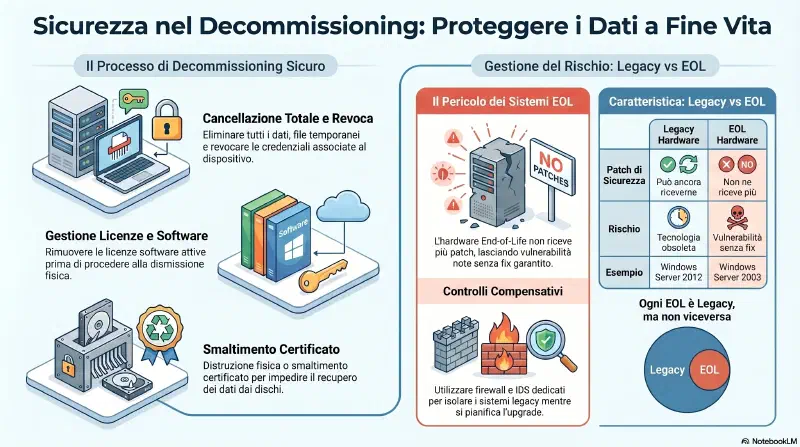
Il ritiro di hardware che non serve piu' e' un aspetto critico della sicurezza IT spesso sottovalutato. Un dispositivo dismesso male e' un data breach in attesa di succedere.
Il rischio: hardware che contiene dati sensibili, credenziali, log, configurazioni. Se smaltito senza cancellazione sicura, chiunque trovi il disco puo' recuperare quei dati.
Il processo corretto di decommissioning:
- Cancellazione di tutti i dati (inclusi file temporanei e backup)
- Revoca di credenziali e account associati al dispositivo
- Rimozione delle licenze software
- Distruzione fisica o smaltimento certificato dell'hardware
Legacy hardware vs EOL hardware — distinzione importante per l'esame:
| Legacy hardware | EOL hardware | |
|---|---|---|
| Definizione | Vecchio, superato da tecnologia piu' recente | Fine vita dichiarata dal produttore |
| Patch di sicurezza | Puo' ancora riceverne | Non ne riceve piu' |
| Rischio | Tecnologia obsoleta | Vulnerabilita' note senza fix garantito |
| Esempio | Server con Windows Server 2012 ancora supportato | Windows Server 2003 (EOL 2015) |
Ogni EOL e' legacy, ma non ogni legacy e' EOL. L'EOL e' il caso piu' pericoloso: le CVE vengono scoperte ma il vendor non rilascia patch.
Tre azioni per gestire legacy e EOL:
- Inventario e piano di dismissione: sapere cosa hai, decidere quando va dismesso
- Compensating controls: firewall, antivirus, IDS dedicati al legacy/EOL isolato — riduzione del rischio mentre aspetti la sostituzione
- Upgrade: sostituire quando possibile per eliminare il problema alla radice, non rattopparlo
Decommissioning non e' "spegnere e dimenticare". Hardware dismesso senza cancellazione sicura e' un vettore di data leakage. Il processo formale deve includere data wiping, revoca credenziali e smaltimento fisico certificato.
Exam tip: EOL = niente piu' patch dal vendor. Legacy = vecchio ma potenzialmente ancora supportato. Sul Security+ le domande su EOL enfatizzano il rischio di vulnerabilita' non patchabili e la necessita' di compensating controls o sostituzione.
Protecting Data#
mindmap
root((Protecting Data))
Tre stati
At Rest disco
FDE BitLocker FileVault
Column encryption DB
In Transit rete
TLS HTTPS VPN
Hybrid encryption
In Use RAM CPU
Secure Enclave TEE
Intel SGX
DLP
Network appliance
Keyword e regex
Dezippa prima di scan
Software endpoint
Fisico blocco USB
Primo passo classificare
Database Security
Column encryption
Tokenization vault
Password come hash salted
Removable Media
USB blocking
Write-block
MDM policy
Encryption vs ACL
ACL bypassabile su altro PC
Encryption senza chiave inutile
I dati sono la risorsa piu' preziosa di un'organizzazione dopo le persone. Gli attaccanti li vogliono per tre ragioni: monetizzazione diretta (carte di credito, identita'), spionaggio industriale (dati proprietari), o disruption (ransomware che cifra tutto). La protezione agisce su due fronti: confidenzialita' (chi puo' vederli) e disponibilita' (non perderli, non farli cifrare da ransomware).
La policy di sicurezza definisce le classificazioni dei dati (Confidential, PII, Proprietary) — il DLP le usa per sapere cosa bloccare.
Exam tip — primo passo del DLP: prima di deployare qualsiasi regola DLP, il primo passo e' sempre classificare i dati. Il DLP non sa cosa e' sensibile finche' non glielo dici. Solo dopo aver applicato le classificazioni puoi scrivere regole ("blocca email con allegati classificati Confidential") o bloccare upload verso cloud storage. DLP senza classificazione = cieco.
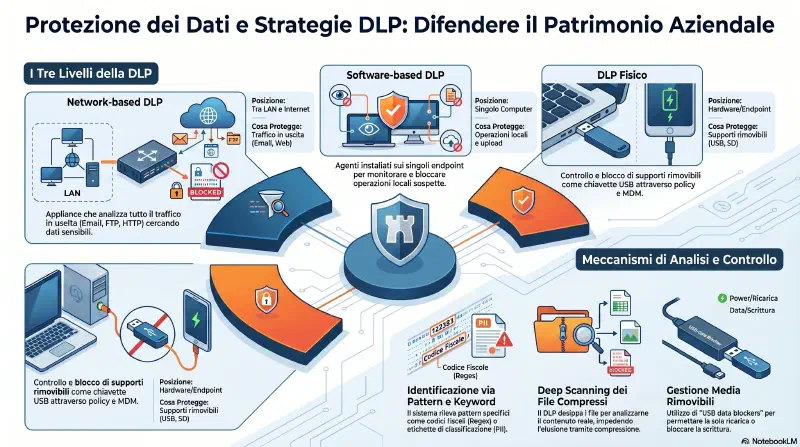
Data Loss Prevention (DLP)#
Data exfiltration = trasferimento non autorizzato di dati fuori dall'organizzazione. Puo' essere un attaccante esterno che usa malware, o un insider malevolo. Il DLP e' l'insieme di tecniche e tecnologie per prevenirlo.
DLP non e' un singolo tool ma un ombrello che copre livelli diversi:
Livelli del DLP
│
├─ Fisico: blocco USB flash drive, controllo removable media
│
├─ Network-based DLP: appliance che analizza tutto il traffico in uscita
│ tutto il traffico → [DLP appliance] → internet
│ cerca keyword, pattern, dati classificati
│
└─ Software-based DLP: installato sul singolo endpoint
analizza le operazioni locali, blocca i tentativi di esfiltrazioneCome funziona il network-based DLP
Tutto il traffico in uscita passa attraverso un appliance. L'admin configura cosa cercare:
- Keyword specifiche (es. codename progetto "DOH" → ogni email con quella parola viene bloccata)
- Pattern regex (es. SSN americano:
###-##-####→ identifica numeri previdenza sociale) - Etichette di classificazione (es. "CONFIDENTIAL", "PII", "PROPRIETARY")
Cosa scansiona:
- Email e allegati (documenti, fogli Excel, presentazioni, database)
- Traffico FTP e HTTP
- File compressi: li dezippa e analizza il contenuto — non basta zippare per eluderlo
- Dati cifrati in uscita: non puo' leggerli, ma rileva che stanno uscendo dati cifrati e allerta
Quando trova un match: blocca il trasferimento, notifica il security administrator, notifica l'utente (opzionale).
Esempio concreto (Gibson): un'organizzazione scansiona tutte le email in uscita cercando il pattern SSN (###-##-####). Un dipendente manda per sbaglio un foglio Excel con dati clienti. Il DLP rileva il pattern, blocca l'email, allerta il security admin.
PII — Personally Identifiable Information: qualsiasi dato che permette di identificare un individuo (nome, SSN, data di nascita, email, indirizzo). E' una delle categorie piu' cercate dal DLP perche' e' regolamentata per legge (GDPR in Europa, HIPAA per dati sanitari USA).
Limite contro esfiltrazione cifrata: se l'attaccante cifra i dati prima di mandarli fuori, il DLP non legge il contenuto. Puo' pero' rilevare volumi insoliti di traffico cifrato in uscita e generare un alert.
| Tipo DLP | Dove gira | Cosa blocca |
|---|---|---|
| Network-based | Appliance tra LAN e internet | Traffico in uscita (email, FTP, HTTP) |
| Software-based | Singolo endpoint | Operazioni locali (copia file, upload) |
| Fisico | Policy + MDM | USB, removable media |
DLP = prevenire che i dati escano, non solo proteggere chi puo' vederli. Copre livelli fisici (USB), di rete (appliance DLP) e di endpoint (software DLP). L'esame distingue i tre livelli.
Exam tip: "data exfiltration" = dati che escono senza autorizzazione. DLP e' la famiglia di controlli che lo previene. Il DLP dezippa i file compressi prima di scansionarli — comprimere non basta per eluderlo.
Removable Media#
Removable media = qualsiasi supporto di archiviazione che si puo' collegare a un computer e usare per copiare dati. Esempi: USB flash drive, hard disk esterni, SD card, CD, DVD. Anche gli smartphone moderni rientrano in questa categoria per la loro capacita' di archiviazione.
Due vettori di rischio:
- Esfiltrazione: un dipendente (o attaccante con accesso fisico) copia dati sensibili su una chiavetta e la porta fuori
- Infezione: malware viene introdotto in rete tramite un dispositivo infetto collegato a un sistema
Controlli tecnici:
| Controllo | Cosa fa |
|---|---|
| Blocco USB completo | Il sistema non riconosce nessun USB storage — ne' lettura ne' scrittura |
| USB data blocker (write-block) | Permette la ricarica ma blocca il trasferimento dati — solo lettura o solo carica |
| Policy MDM | Blocco removable media gestito centralmente su tutti gli endpoint |
Il DLP (sezione precedente) completa questo strato: anche se qualcuno riesce a collegare un dispositivo, il DLP rileva e blocca il trasferimento se i dati sono classificati.
Protecting Confidentiality with Encryption#
Tre stati dei dati — tre superfici di attacco diverse: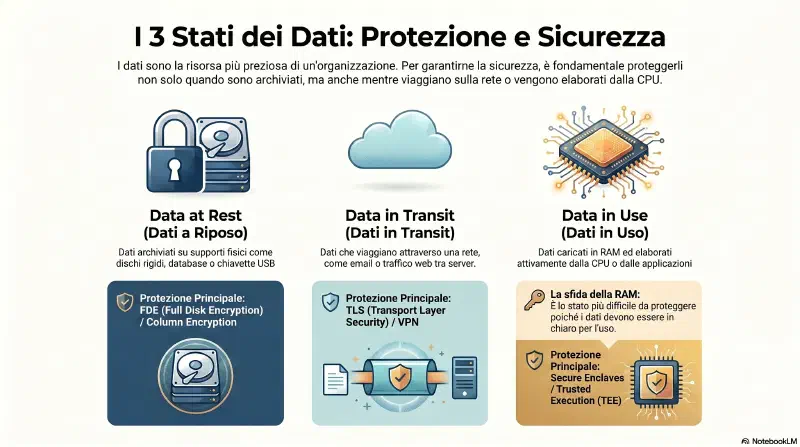
| Stato | Definizione | Protezione principale |
|---|---|---|
| Data at rest | Dati fermi su un supporto (disco, USB, database) | Disk encryption, FDE, column encryption |
| Data in transit | Dati che viaggiano sulla rete | TLS, VPN, HTTPS |
| Data in use | Dati attivamente elaborati in RAM/CPU | Secure enclaves, trusted execution |
Il Security+ chiede principalmente at rest e in transit.
Perche' data in transit usa Hybrid Encryption (non solo asymmetric)
TLS — il protocollo che protegge HTTPS, VPN, email sicura — non usa mai solo crittografia asimmetrica o solo simmetrica. Usa entrambe in sequenza: e' questa combinazione che si chiama hybrid encryption.
| Fase | Tipo | Algoritmo tipico | Perche' |
|---|---|---|---|
| Handshake | Asimmetrica | RSA / ECDH | Scambia in sicurezza la chiave simmetrica |
| Dati | Simmetrica | AES-256 | Cifra il traffico reale ad alta velocita' |
- Asimmetrica da sola: troppo lenta per cifrare stream di dati — opera su blocchi piccoli, ha overhead computazionale elevato.
- Simmetrica da sola: risolve la velocita' ma ha il problema della distribuzione della chiave — come trasmetti la chiave condivisa in modo sicuro su un canale non sicuro?
- Hybrid: l'asimmetrica risolve il problema della distribuzione (scambia la chiave simmetrica in sicurezza), poi la simmetrica cifra i dati velocemente.
Exam trap: "best encryption method for data in transit" = Hybrid encryption. Non asimmetrica da sola (troppo lenta per bulk data). Non simmetrica da sola (problema di distribuzione della chiave). La risposta corretta e' sempre la combinazione.
Perche' l'encryption batte le ACL
Le ACL (Access Control Lists) di NTFS sembrano proteggere i file — ma sono controlli a livello OS. Se togli il disco fisico e lo monti come drive secondario su un'altra macchina in cui sei administrator, puoi prendere ownership dei file e leggere tutto. Le ACL non esistono piu'.
La cifratura non ha questo problema: la chiave di decifratura non sta nel disco. Senza la chiave il contenuto e' illeggibile ovunque tu porti il disco — altro PC, altro OS, altro admin. Non importa.
ACL (NTFS):
disco rubato → monta su altro PC → login admin → take ownership → leggi tutto ✗
Encryption:
disco rubato → monta su altro PC → leggi solo dati cifrati → niente chiave → niente dati ✓Livelli di applicazione dell'encryption
Non si cifra per forza tutto — si sceglie il livello giusto in base ai requisiti:
- Intero disco (FDE) → BitLocker, FileVault, SED — protegge tutto, incluso OS
- Partizione o volume → subset del disco
- File o directory specifica → protezione granulare
- Campi specifici del database → vedi sezione Database Security
Exam tip: la primary method per proteggere la confidenzialita' dei dati e' encryption + strong access controls. Solo ACL non basta — un disco rubato bypassa le ACL ma non bypassa la cifratura.
Database Security#
I database contengono spesso le informazioni piu' sensibili: credenziali, dati di pagamento, PII. Ci sono due approcci per cifrarli:
Cifratura dell'intero database: possibile ma raro in produzione — troppo costoso in termini di CPU, rallenta ogni query.
Cifratura a livello di campo (column encryption): si cifrano solo le colonne che contengono dati sensibili. Esempio con tabella Customers:
Tabella Customers
┌──────────────┬──────────────┬──────────────┬────────────────────┬───────────────────┐
│ customer_id │ last_name │ first_name │ credit_card_num │ security_code │
├──────────────┼──────────────┼──────────────┼────────────────────┼───────────────────┤
│ 1001 │ Rossi │ Mario │ [CIFRATO] │ [CIFRATO] │
│ 1002 │ Bianchi │ Anna │ [CIFRATO] │ [CIFRATO] │
└──────────────┴──────────────┴──────────────┴────────────────────┴───────────────────┘Solo credit_card_num e security_code sono cifrati — i campi non sensibili no. Si risparmia CPU senza esporre i dati critici.
Altre tecniche di protezione del database:
- Password come hash / salted hash: le password non si salvano in chiaro — si salva solo l'hash. Con il salt, due utenti con la stessa password hanno hash diversi (vedi Cap 10 per i dettagli).
- Tokenization: sostituisce il dato sensibile con un token casuale (placeholder privo di valore). Il dato reale sta in un vault separato. Esempio: al posto del numero carta
4111-1111-1111-1111nel DB comparetok_8x7kQp2m. Se il DB viene compromesso, i token sono inutili senza accesso al vault.
Database column encryption protegge i campi sensibili senza cifrare tutto il database — e' il pattern piu' comune in produzione. Exam keyword: "database field (column) encryption".
Exam tip: "data at rest" = dati fermi su un supporto. L'encryption e' il controllo primario. Le ACL da sole non bastano — un disco rubato bypassa NTFS ma non bypassa BitLocker.
Protecting Data in Use#
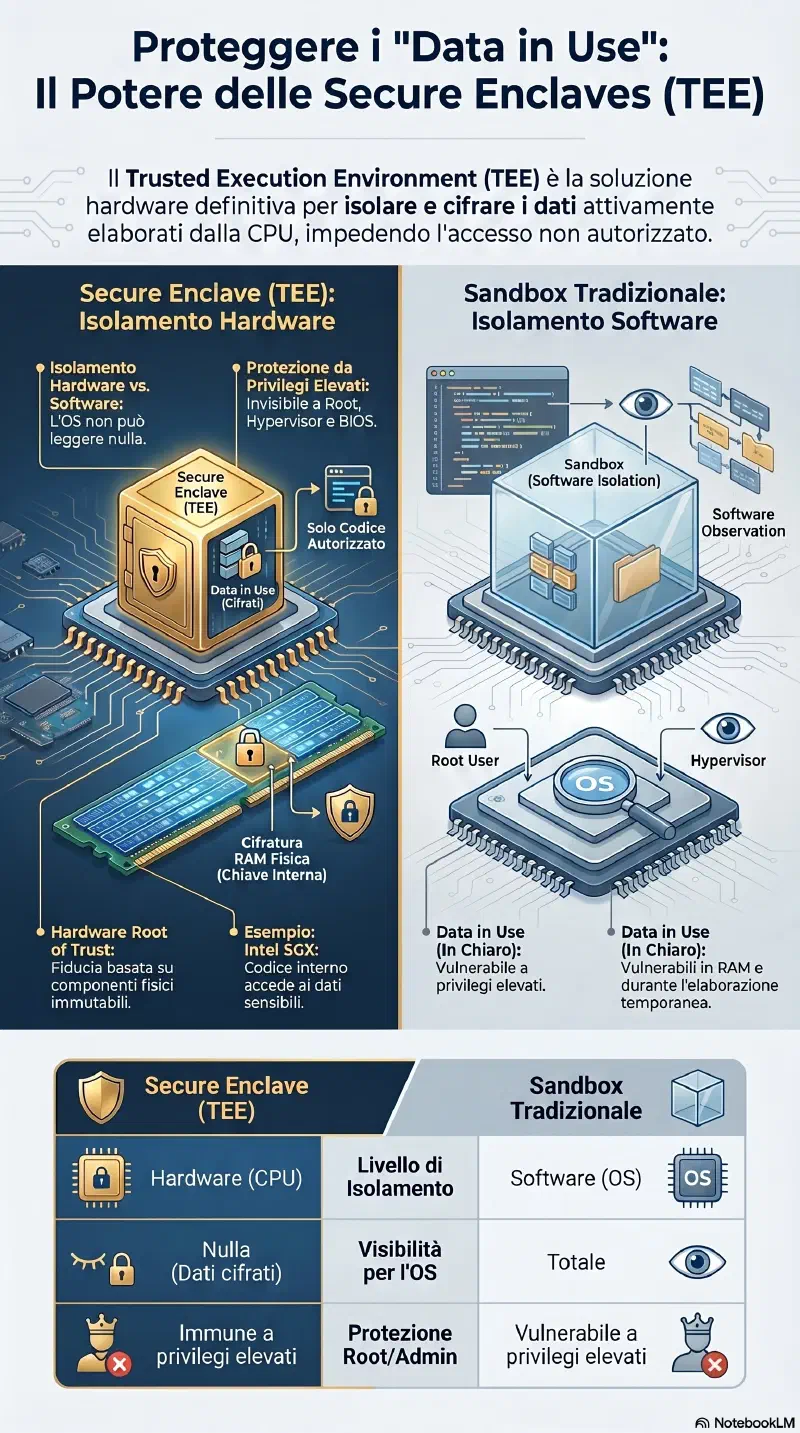
Data in use = dati attivamente elaborati dalla CPU o presenti in RAM. Sono il caso piu' difficile da proteggere: per essere usati, devono essere in chiaro in memoria, almeno temporaneamente.
Esempi concreti:
Scenario 1 — PDF cifrato
Apri il file → sistema carica la chiave di decifratura in RAM
→ CPU decifra il contenuto
In quel momento: la chiave è in chiaro in memoria
Rischio: memory scraping, cold boot attack
Scenario 2 — Login con password
Digiti la password → CPU la confronta con l'hash nel database
In quel momento: la password è in RAM in chiaro (per ms)
Rischio: malware che legge la memoria del processo di autenticazione
Scenario 3 — Query su colonna cifrata del DB
DB riceve la query → decifra il campo per elaborarlo
In quel momento: il numero di carta di credito è in chiaro in RAM
Rischio: un attaccante con accesso al processo del DBSecure Enclave / TEE (Trusted Execution Environment)
La soluzione hardware al problema del data in use. L'analogia con la sandbox e' corretta ma con una differenza critica:
Sandbox (isolamento software):
[Processo A] [Processo B] [Enclave]
↑ ↑ ↑
│ │ │
[Sistema Operativo]────────┘
↑
l'OS puo' leggere TUTTO
(incluso "Processo A" e "Processo B")
Se l'OS è compromesso → tutto è esposto
Secure Enclave (isolamento hardware):
[Processo A] [Processo B] [ENCLAVE]
↑ ↑ ↑
│ │ │ ← memoria cifrata a livello CPU
[Sistema Operativo] │ ← l'OS vede solo bytes cifrati
↑ │
l'OS NON puo' leggere l'enclave
Nemmeno hypervisor o BIOS ci entrano
→ hardware lo impedisce fisicamenteL'enclave e' isolata dall'esterno tramite hardware: la CPU cifra quella regione di RAM fisicamente, e la chiave di decifratura non lascia mai il chip. Anche root, anche l'hypervisor, anche il BIOS — nessuno puo' leggere il contenuto dell'enclave dall'esterno.
Funzioni integrate nell'enclave :
| Funzione | Dettaglio |
|---|---|
| Boot ROM dedicato | L'enclave ha il suo processo di avvio, separato dall'OS |
| True random number generator | Genera numeri casuali hardware — non pseudo-random software |
| Real-time memory encryption | Cifra i dati in entrata/uscita dalla memoria in tempo reale |
| Chiavi crittografiche built-in | Chiavi hardcoded nel chip, non modificabili, usate come root of trust |
| AES in hardware | Cifratura AES eseguita direttamente nell'hardware, non in software |
| Process monitoring | Monitora i processi del sistema, specialmente durante il boot |
Queste funzioni sono disponibili su ogni dispositivo moderno con secure enclave — telefono, laptop, tablet. Il nome cambia per produttore (Apple: "Secure Enclave", Intel: SGX) ma le capacita' sono le stesse.
Intel SGX (Software Guard Extensions): implementazione concreta di secure enclave. Il developer definisce quale porzione del codice e dei dati deve girare nell'enclave. SGX crea quella regione in RAM, la cifra con chiave interna alla CPU, e solo il codice dentro l'enclave puo' accedervi.
Esempio reale: un password manager usa SGX per mantenere il vault decifrato nell'enclave durante l'uso. Il processo OS che gestisce l'interfaccia grafica non vede le password in chiaro — le riceve solo attraverso chiamate all'enclave.
Exam tip: data in use = il caso piu' difficile da proteggere. Secure enclave / TEE = isolamento hardware (non software). La differenza con la sandbox: l'OS puo' leggere tutto in una sandbox, non puo' leggere niente in un'enclave hardware. Tecnologia: Intel SGX.
Cloud Concepts#
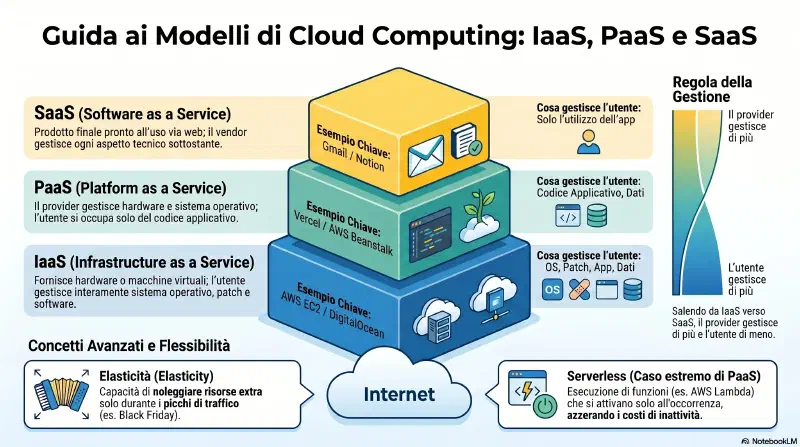
mindmap
root((Cloud Concepts))
Delivery Models
SaaS app completa
Gmail Notion
Vendor patcha tutto
PaaS piattaforma
Vercel Heroku
Serverless FaaS
IaaS infrastruttura
EC2 Hetzner
Tu gestisci OS
Shared Responsibility
Dati sempre cliente
OS IaaS cliente
OS PaaS SaaS provider
Deployment Models
Public tutti
Private una org
Community gruppo condiviso
Hybrid mix modelli
Multi-cloud provider diversi
Provider
MSP IT generico
MSSP security H24
CSP cloud hardware
Considerazioni 6
Availability HA
Resilience sotto stress
Cost
Responsiveness velocita
Scalability crescita
Segmentation VLAN cloud
On-Premises vs Off
On totale controllo
Off data residency risk
Single pane of glass
API e Microservices
Auth Authz TLS
Microservizio fa una cosa
Security containment
Il cloud computing e' accedere a risorse di calcolo da una location diversa dal proprio computer locale, tipicamente via internet. Il punto chiave: non sai dove fisicamente si trova il server. Gmail potrebbe girare su un data center in Virginia o in Utah — non lo sai e non importa.
Il concetto di elasticity (sezione Virtualization) e' la base che rende il cloud utile in picchi di traffico. Esempio Gibson: Amazon durante il Black Friday aveva i server al limite della capacita'. L'anno successivo ha noleggiato server cloud solo per quella settimana. Da quella lezione e' nato Amazon EC2.
SaaS, PaaS, IaaS — i tre delivery model#
Cosa gestisci TU vs il provider
SaaS PaaS IaaS
───── ───── ─────
Applicazione Provider TU TU
Runtime/Framework Provider Provider TU
OS / Patch Provider Provider TU
Hardware Provider Provider Provider
Regola rapida: salendo da IaaS a SaaS, il provider gestisce sempre di piu' — tu gestisci sempre di meno.
SaaS — Software as a Service
Usi solo l'applicazione finale. Non hai accesso a nessuno strato sottostante.
| Esempio | Cosa fai | Cosa non gestisci |
|---|---|---|
| Gmail | Scrivi email | Server, OS, database, patch |
| Notion | Prendi note | Niente — usi solo l'app |
| GitHub (cloud) | Gestisci repo | Nessun server |
Exam keyword: "web-based email = SaaS". Il vendor gestisce tutto, incluse le patch. Tu usi solo il prodotto finale.
PaaS — Platform as a Service
Il provider gestisce hardware, OS, runtime, patch. Tu porti il codice e l'applicazione. Non interagisci mai con l'OS sottostante.
| Esempio | Cosa fai | Cosa gestisce il provider |
|---|---|---|
| Vercel (il blog Hugo) | Fai push del codice | Build, deploy, CDN, certificati TLS, scaling |
| Heroku | Carichi app Node.js | OS, runtime Node, scaling, patch |
| AWS Elastic Beanstalk | Carichi il codice | EC2, OS, load balancer, auto-scaling |
PaaS non e' una VPS. Una VPS base e' IaaS: ti danno Linux, ci installi tutto tu. PaaS e' una VPS dove il provider gestisce anche OS e runtime — tu non hai mai accesso a ssh sulla macchina.
Serverless — il caso estremo di PaaS
Con Lambda (AWS) o Cloud Functions (GCP) non esiste nemmeno il concetto di server che gira in attesa. Esempio concreto:
Scenario: ogni foto caricata su S3 deve essere ridimensionata
Senza serverless:
Server Express.js sempre acceso → polling S3 → ridimensiona
Costo: 24/7 anche se arriva 1 foto all'ora
Con AWS Lambda:
1. Scrivi la funzione Python resize_image()
2. La carichi su Lambda
3. Dici: "eseguila quando arriva un file in questo bucket S3"
→ Arriva foto → Lambda fa girare la funzione (200ms) → la spegne
→ Paghi solo quei 200ms
→ Nessun server da gestire, nessun OS, nessuna patchAltro esempio: API endpoint. Invece di un server Node.js sempre attivo, ogni richiesta HTTP fa girare la Lambda function per il tempo necessario, poi si spegne.
FaaS — Function as a Service e' il termine formale per il modello serverless. I due termini descrivono la stessa cosa:
| Termine | Cos'e' |
|---|---|
| Serverless | Nome comune / marketing |
| FaaS (Function as a Service) | Nome tecnico formale della stessa cosa |
| Lambda, Cloud Functions | Implementazioni concrete di FaaS |
Ogni funzione ha tre proprieta' chiave per l'esame:
| Proprieta' | Significato |
|---|---|
| Event-triggered | Non gira in attesa — si avvia solo su evento (HTTP request, file upload, messaggio in coda) |
| Ephemeral | Vive solo durante l'esecuzione. Risponde, si spegne. |
| Stateless | Ogni esecuzione parte da zero, nessuna memoria delle precedenti |
Implicazione di sicurezza: il developer scrive la logica server-side, ma il container stateless e' gestito dal cloud provider (third-party). Tutta la sicurezza dell'OS sottostante e' responsabilita' del provider — non tua.
Exam keyword: FaaS = Function as a Service. Serverless non significa "nessun server" — significa che il server e' gestito dal provider. La sicurezza dell'OS in serverless e' sempre in capo al third-party (cloud provider).
IaaS — Infrastructure as a Service
Il provider ti affida l'hardware (o la VM equivalente). Tu gestisci tutto dall'OS in su: installazione, configurazione, patch, software. Soluzione "self-managed".
| Esempio | Cosa ti danno | Cosa gestisci tu |
|---|---|---|
| Hetzner VPS (Mustache) | VM con Linux di base | OS, Suricata, SIEM, patch, servizi |
| AWS EC2 | VM con OS opzionale | Tutto sopra l'hardware |
| DigitalOcean Droplet | VM con Ubuntu | Tutto sopra l'hardware |
IaaS e' utile quando hai bisogno di controllo totale sull'ambiente — o quando vuoi ridurre il footprint fisico nel tuo data center senza perdere il controllo dell'OS.
| SaaS | PaaS | IaaS | |
|---|---|---|---|
| Gestione OS | Provider | Provider | Tu |
| Patch | Provider | Provider | Tu |
| Codice app | Provider | Tu | Tu |
| Controllo | Minimo | Medio | Massimo |
| Esempio | Gmail | Vercel | Hetzner/EC2 |
| Keyword | "fully managed app" | "fully managed platform" | "self-managed" |
Exam tip: SaaS = app completa via internet (Gmail, web-based email). PaaS = piattaforma gestita, il vendor fa OS e patch. IaaS = hardware/VM in affitto, tu gestisci tutto. Serverless = caso estremo di PaaS, zero server da configurare.
Shared Responsibility Model#
Questo e' il frame che trasforma SaaS/PaaS/IaaS da "tipi di cloud" a "modelli di responsabilita' divisa". L'esame non chiede solo cosa sono — chiede chi e' responsabile di cosa in ogni modello.
Regola chiave: il provider e' responsabile della sicurezza del cloud. Il cliente e' responsabile della sicurezza nel cloud.
| Livello | IaaS | PaaS | SaaS |
|---|---|---|---|
| Dati | Cliente | Cliente | Cliente |
| Identita' / IAM | Cliente | Cliente | Condivisa |
| Applicazione | Cliente | Cliente | Provider |
| OS / Patch | Cliente | Provider | Provider |
| Runtime | Cliente | Provider | Provider |
| Virtualizzazione | Provider | Provider | Provider |
| Storage fisico | Provider | Provider | Provider |
| Hardware | Provider | Provider | Provider |
La riga critica: i dati sono sempre responsabilita' del cliente, anche in SaaS. Se perdi i dati di Gmail per un tuo errore (cancellazione, account compromesso), Google non te li restituisce.
Misconfig nel cloud = errore del cliente, non del provider. Il Capital One breach del 2019 (WAF mal configurato su AWS) era errore del cliente, non di AWS.
Exam keyword: "shared responsibility". In qualsiasi modello cloud, i dati restano responsabilita' del cliente. L'hardware e' sempre del provider. La linea di confine varia per SaaS/PaaS/IaaS.
Cloud Deployment Models#
Quattro modelli che descrivono dove risiede il cloud e chi puo' usarlo:
Public Cloud — disponibile a chiunque voglia pagare. Infrastruttura condivisa tra tutti i clienti del provider.
Esempi reali famosi:
- Netflix su AWS: dopo una corruzione del database nel 2008, Netflix ha migrato tutta l'infrastruttura su AWS. Oggi gira quasi interamente su public cloud.
- Capital One data breach 2019: Capital One girava su AWS. Un WAF mal configurato ha esposto oltre 100 milioni di record di clienti. Caso di studio classico su errori di configurazione nel public cloud.
- Dropbox: ha iniziato su AWS, poi ha costruito la propria infrastruttura — esempio di migrazione da public a private.
Private Cloud — cloud creato per un singolo cliente. Puo' essere gestito internamente o da un provider terzo, ma l'accesso e' esclusivo.
Esempi reali famosi:
- CIA / US Intelligence Community: ha firmato un contratto da $600M con AWS per un private cloud dedicato (AWS GovCloud) — nessun altro cliente accede a quella infrastruttura.
- JPMorgan Chase: una delle banche piu' grandi al mondo gestisce un private cloud interno con migliaia di applicazioni. Motivazione: compliance finanziaria e controllo totale sui dati.
- Industria nucleare e difesa: per definizione non possono mettere dati operativi su public cloud — usano private cloud on-premises o dedicati.
Community Cloud — condiviso da un gruppo di organizzazioni con interessi, requisiti di sicurezza o obblighi normativi comuni.
Esempi reali famosi:
- Microsoft GCC (Government Community Cloud): cloud Microsoft riservato esclusivamente ad agenzie governative USA federali, statali e locali. Non accessibile a privati. Soddisfa FedRAMP e altri requisiti di compliance governativa.
- AWS GovCloud: stessa idea — regioni AWS fisicamente separate, accessibili solo a entitla' governative USA verificate.
- GÉANT: rete cloud europea condivisa tra universita' e centri di ricerca. Risorse computazionali e storage condivisi solo tra istituzioni accademiche europee.
Hybrid Cloud — combinazione di due o piu' modelli. Le parti mantengono identita' separata ma sono collegate, spesso in modo trasparente per gli utenti.
Esempi reali famosi:
- BMW: usa Azure per workload customer-facing e analisi dati, ma mantiene sistemi di produzione e IP industriale su infrastruttura privata. Il confine e' invisibile agli utenti finali.
- Banche retail: dati dei clienti e core banking on-premises (compliance, bassa latenza), app mobile e servizi digitali su public cloud. L'utente dell'app non vede il confine.
- Adobe Creative Cloud: le app girano localmente sul tuo Mac (private), i file si sincronizzano su cloud Adobe (gestito). Hybrid dal punto di vista dell'utente.
| Modello | Chi puo' accedere | Gestito da | Esempio |
|---|---|---|---|
| Public | Chiunque paghi | Provider | AWS, Azure, GCP |
| Private | Una sola organizzazione | Organizzazione o provider dedicato | CIA GovCloud, JPMorgan |
| Community | Gruppo con interessi comuni | Provider o comunita' | Microsoft GCC, GÉANT |
| Hybrid | Dipende dal componente | Mix | BMW, banche |
Exam tip: public = aperto a tutti. Private = una sola organizzazione. Community = gruppo con requisiti condivisi (es. governo, ricerca). Hybrid = mix di due o piu' modelli, con identita' separate ma collegate.
Multi-cloud#
Multi-cloud = risorse da due o piu' cloud provider distinti. Concetto diverso da hybrid cloud — la distinzione e' critica per l'esame:
| Multi-cloud | Hybrid cloud | |
|---|---|---|
| Cosa combina | Provider diversi | Modelli diversi (public + private) |
| Esempio | AWS + Azure | AWS (public) + datacenter interno (private) |
| Entrambi public? | Si, possibile | No — per definizione mescola modelli |
Esempio: un'organizzazione usa EC2 di AWS per il compute e Azure Blob Storage per i backup. Entrambi sono public cloud — e' multi-cloud, non hybrid.
Pro: resilienza. Se AWS va down, Azure regge. Nessun vendor lock-in.
Contro: complessita'. Il team IT deve conoscere e mantenere due ambienti separati, con tool, IAM, network e security policy diversi per ciascuno. Piu' complessita' = piu' superficie di attacco, piu' rischio di errori di configurazione.
Sfide operative concrete del multi-cloud (da tenere per l'esame):
- Log eterogenei: ogni provider scrive log con formato e terminologia diversi. Correlare eventi tra AWS e Azure richiede normalizzazione — non puoi semplicemente unirli e cercare.
- Mismatch di configurazione: i provider non si parlano direttamente. Devi configurare separatamente IAM, firewall, autenticazione su ciascuno. Un errore su un provider non si replica sull'altro — rimane invisibile finche' non crea un incidente.
- Dati in transito tra provider: quando i dati passano da un cloud all'altro attraverso internet pubblico, devi garantire cifratura in transito. Ogni trasferimento e' un momento di esposizione.
Exam trap: multi-cloud non e' hybrid cloud. Multi-cloud = due provider. Hybrid = due modelli di deployment (es. public + private).
APIs e Microservices#
Esempio concreto: Amazon.com mostra il tracking dei pacchi. Non gestisce internamente i dati di UPS o FedEx — chiama le API dei singoli corrieri passando il tracking ID, riceve i dati e li mostra. L'input entra, i dati escono.
Vulnerabilita' delle API — tre aree critiche da proteggere:
| Area | Rischio se assente | Soluzione |
|---|---|---|
| Authentication | Chiunque chiama l'API | Password + MFA, API key, OAuth |
| Authorization | Utente autenticato accede a dati altrui | Ruoli diversi (developer vs app vs admin) |
| Transport security | Traffico intercettabile | TLS obbligatorio |
Esempio reale: i primi termostati wireless Nest mandavano dati in chiaro su internet — esponevano orari di casa, abitudini degli occupanti. TLS avrebbe cifrato il traffico e impedito l'intercettazione.
Indicatori di attacco via API:
- Dati trapelati online → probabile esfiltrazione via API
- Siti web compromessi → API dell'applicazione web attaccata
- Volumi anomali di chiamate API → brute force o scraping
Microservices
Un microservizio e' un modulo di codice che fa una cosa sola bene. Riceve input, processa, restituisce output. Non e' legato a un'azienda specifica — e' riusabile in qualsiasi applicazione.
Differenza con API classica (web service):
API classica (web service):
Tracking UPS → chiama API UPS (specifica per UPS)
Tracking FedEx → chiama API FedEx (specifica per FedEx)
→ codice diverso per ogni corriere
Microservizio:
Tracking ID → microservizio determina il corriere
→ chiama l'API giusta
→ restituisce i dati
→ un solo modulo per tutti i corrieri
→ riusabile in qualsiasi app senza modificheNota: Gibson usa "microservice" in senso semplificato — descrive un modulo riusabile non legato a un vendor. Non e' il concetto architetturale di microservizi vs monolite che conosci come developer (deploy indipendenti, fault isolation, scaling per servizio, service discovery). Il punto di contatto e' che un microservizio architetturale rispetta anche la definizione Gibson: piccolo, fa una cosa, espone un'API. Per il Security+ basta la definizione Gibson.
Monolite vs Microservizi
| Monolite | Microservizi | |
|---|---|---|
| Struttura | Un singolo eseguibile — UI, business logic, auth tutto insieme | Servizi separati, ognuno espone un'API |
| Aggiornamenti | Cambia una cosa → rebuild e deploy di tutto | Aggiorna solo il microservizio interessato |
| Scalabilita' | Scala tutto o niente | Scala solo il servizio sotto pressione |
| Fault isolation | Un errore puo' abbattere tutto | Un microservizio down non ferma gli altri |
| Sicurezza | Un perimetro per tutto | Ogni microservizio ha la propria security policy |
Flusso architetturale:
Client
└─→ API Gateway ← punto unico di ingresso, gestisce routing
├─→ Microservizio A (es. autenticazione) └─→ Database A
├─→ Microservizio B (es. pagamenti) └─→ Database B
└─→ Microservizio C (es. notifiche) └─→ Database CVantaggio di sicurezza chiave: security containment built-in. Il microservizio di autenticazione ha le sue policy di sicurezza. Quello dei pagamenti ha le sue. Una compromissione di un microservizio non si propaga automaticamente agli altri.
Exam tip: API = interfaccia tra sistemi, va protetta con auth + authz + TLS. Microservizio = modulo che fa una cosa, non legato a un'azienda specifica, riusabile. Indicatore di attacco API = data leak online.
MSSP — Managed Security Service Provider#
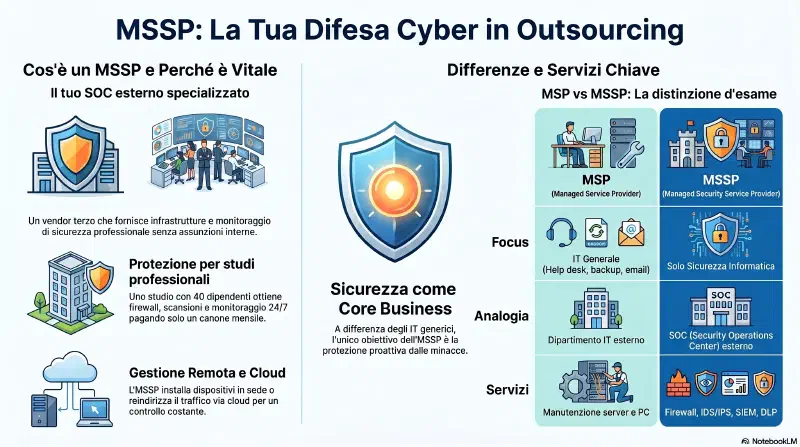
Esempio concreto: uno studio commercialista con 40 dipendenti gestisce dichiarazioni dei redditi, conti bancari, PII di centinaia di clienti. Hanno un sysadmin part-time per i PC, zero figure di security. Non possono permettersi un SOC analyst, un firewall engineer, un threat intelligence specialist.
Ingaggiano un MSSP come Secureworks o Trustwave. Il contratto include:
- NGFW installato in sede, configurato e monitorato da remoto dall'MSSP
- Scansioni di vulnerabilita' mensili
- Filtro antispam/antiphishing sulle email
- SOC 24/7: se alle 3 di notte parte un attacco brute force, gli analisti dell'MSSP lo vedono e lo bloccano
Lo studio paga una fee mensile. Non ha assunto nessuno. Ha pero' una copertura che da soli non potrebbero permettersi.
Servizi tipici di un MSSP:
| Categoria | Esempi |
|---|---|
| Perimetro | NGFW, UTM appliance, VPN |
| Rilevamento | IDS/IPS, SIEM gestito, vulnerability scanning |
| Filtraggio | Antispam, antivirus, web content filtering (proxy) |
| Dati | DLP |
| Manutenzione | Patch management |
L'MSSP puo' installare appliance fisiche in sede del cliente e gestirle da remoto, oppure redirigere tutto il traffico attraverso il proprio cloud (cloud-hosted security).
MSP vs MSSP:
MSSP (Managed Security Service Provider): Azienda esterna che fornisce servizi di SOC e sicurezza gestita per conto di terzi — analisti H24, SIEM, EDR, IR inclusi nel servizio.
Esempi in Italia: Fastweb Security, TIM Enterprise Security, Yarix, Cyberoo, Spike Reply. Hook: il SOC in outsourcing. Per aziende che non possono permettersi un SOC interno H24, l'MSSP è la soluzione. Per chi vuole fare carriera nel SOC, gli MSSP sono il posto dove si impara più velocemente — volume altissimo di alert reali.
MSP (Managed Service Provider): Azienda esterna che gestisce servizi IT generici per conto di un cliente — help desk, backup, server, email, rete. Non focalizzato sulla security. Spesso aggiunge servizi MSSP come add-on. Differenza chiave: MSP = IT in outsourcing, MSSP = SOC/security in outsourcing. Entrambi forniscono servizi continuativi (non consulenza a progetto).
| MSP | MSSP | |
|---|---|---|
| Focus | IT generale (help desk, backup, email, server) | Solo security |
| Offre security? | A volte, come add-on | Si, e' il core business |
| Analogia | IT department esterno completo | SOC esterno |
Nella pratica molti MSP aggiungono servizi MSSP al loro catalogo — la distinzione si confonde. Per l'esame: MSP = IT generico, MSSP = security specifica.
MSSP non e' un team di consulenza. La distinzione e' nel tipo di rapporto:
| Security consulting | MSSP | |
|---|---|---|
| Durata | Progetto definito (pen test, audit) | Servizio continuativo 24/7 |
| Output | Report, raccomandazioni | Operazioni di security attive |
| Dopo l'incarico | Se ne vanno | Restano, sempre |
| Analogia | Freelancer per una feature | SaaS sempre acceso |
Un consulente dice "hai queste vulnerabilita', fai queste cose". L'MSSP le gestisce direttamente, ogni giorno, anche di notte. E' il tuo SOC in outsourcing — non un advisor.
Il meccanismo che formalizza il rapporto e' lo SLA (Service Level Agreement): il contratto definisce tempi vincolanti. Respond within X hours = entro quanto dall'alert devono risponderti. Resolve within Y hours = entro quanto devono aver contenuto o risolto. Se non rispettano i tempi, scattano le penali contrattuali. E' un reparto esternalizzato con KPI misurabili, non un consulente che consegna un report e sparisce.
Exam tip: MSSP = third-party vendor che fornisce security services. MSP = IT services in generale (puo' includere security ma non e' il focus). Una piccola azienda senza budget per un SOC interno usa un MSSP.
Cloud Service Provider Responsibilities#
Un CSP (Cloud Service Provider) e' l'entita' che offre uno o piu' servizi cloud tramite uno o piu' deployment model. La differenza tra modelli non e' solo "cosa ti danno" — e' una divisione precisa di responsabilita' tra CSP e cliente, sia per la manutenzione che per la sicurezza.
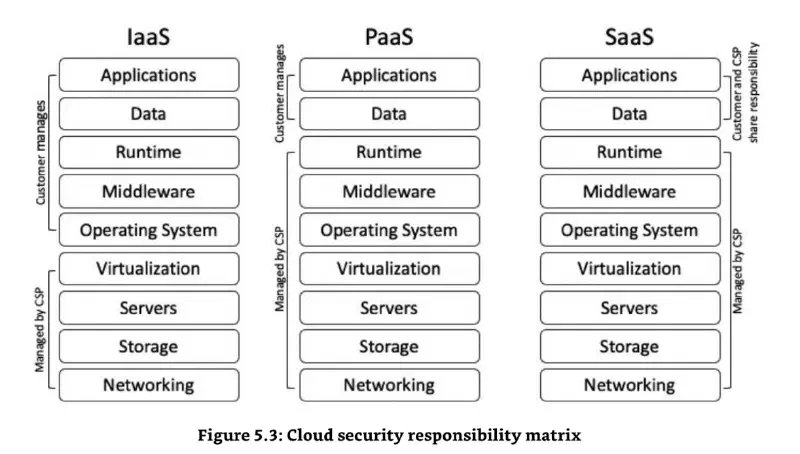
La figura 5.3 (derivata dalla DoD Cloud Computing Security Requirements Guide) mostra la matrice completa. Salendo da IaaS a SaaS, il CSP gestisce progressivamente di piu' — il cliente sempre di meno.
Due termini tecnici nella matrice:
Middleware: software aggiunto all'OS per estenderne le capacita' di base. Esempio Gibson: Apache aggiunto a Linux trasforma il sistema in web server. In PaaS il CSP fornisce e gestisce il middleware — il cliente non lo tocca.
Runtime: ambiente di hosting in cui gira l'applicazione del cliente. In PaaS il CSP affitta accesso allo stesso server a piu' clienti. Ogni cliente gira dentro un container isolato dagli altri. Il runtime e' quello strato di isolamento.
Tre esempi concreti di Gibson per leggere la matrice:
| Modello | Esempio | Cosa gestisce il CSP | Cosa rimane al cliente |
|---|---|---|---|
| SaaS | Gmail | Tutto — server, OS, database, patch, sicurezza infrastruttura | Password forte e diversa dagli altri account |
| PaaS | Container su server | Tutto tranne applicazione e dati | Applicazione e dati |
| IaaS | Server fisico o virtuale in affitto | Solo hardware e networking | OS, runtime, middleware, applicazioni, dati |
Il punto critico di Gmail: Google si occupa della sicurezza dell'infrastruttura, ma la responsabilita' cliente non sparisce — usare una password forte e unica protegge i propri dati.
Il CSP e' anche responsabile della services integration: garantire che tutti gli elementi della soluzione cloud funzionino insieme.
Exam keyword: "shared responsibility model". In IaaS il cliente gestisce OS, runtime e middleware. In PaaS solo applicazione e dati. In SaaS principalmente credenziali e dati propri.
Exam tip: se una domanda chiede chi patcha l'OS in un deployment cloud, la risposta dipende dal modello: IaaS = cliente, PaaS/SaaS = CSP. "Web-based email" o "fully managed app" = SaaS.
Cloud Security Considerations#
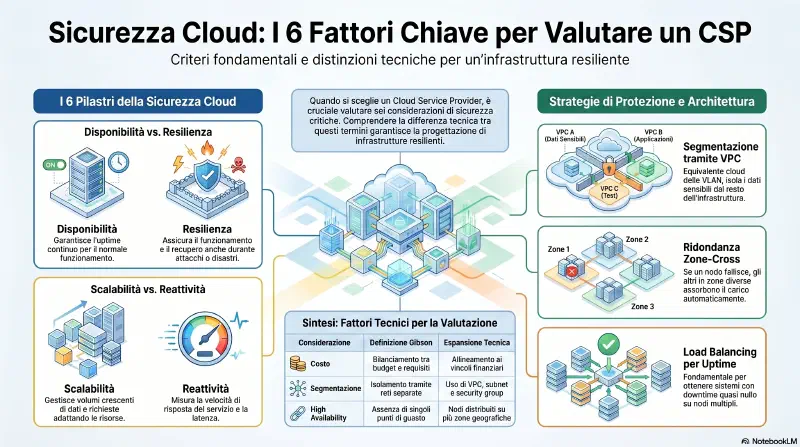
Quando si sceglie un CSP, un'organizzazione deve valutare questi fattori di sicurezza:
| Considerazione | Espansione | Definizione Gibson |
|---|---|---|
| Availability | Alta disponibilita' | Sistema operativo con downtime quasi zero, ottenuto con load balancing su nodi multipli |
| Resilience | Resilienza | Capacita' di mantenere la funzionalita' anche in caso di eventi avversi (disastri, attacchi) — tramite ridondanza e failover |
| Cost | Costo | Bilanciare il costo del servizio con il budget e i requisiti dell'organizzazione |
| Responsiveness | Reattivita' | Velocita' e affidabilita' con cui il servizio risponde alle richieste — misurata in response time e throughput |
| Scalability | Scalabilita' | Capacita' di gestire quantita' crescenti di dati, traffico e richieste senza degradare le performance |
| Segmentation | Segmentazione | Isolamento di dati e applicazioni sensibili tramite reti separate — come le VLAN on-premises, ma nel cloud |
High Availability (HA)
HA non e' sinonimo di ridondanza — e' un livello superiore.
| Concetto | Definizione | Esempio |
|---|---|---|
| Ridondanza | Sistema di riserva disponibile, ma attivazione manuale | Firewall di scorta in magazzino: lo prendi, configuri, inserisci nel rack |
| High Availability | Failover automatico, nessuna interruzione percepibile | Due firewall in coppia: se uno cade, l'altro prende il traffico senza intervento umano |
Configurazioni HA:
| Modalita' | Come funziona | Pro | Contro |
|---|---|---|---|
| Active-Passive | Uno gestisce tutto, l'altro e' in standby | Semplice | Il secondario non fa niente finche' il primario non cade — spreco di risorse |
| Active-Active | Entrambi gestiscono traffico simultaneamente | Nessuno spreco, maggiore throughput | Piu' complesso da configurare |
Cascata di costi: progettare per HA moltiplica i costi a ogni layer. Due firewall HA richiedono due reti ridondanti, che richiedono due alimentazioni ridondanti. A un certo punto l'organizzazione deve decidere: vale il costo del downtime o vale il costo dell'HA?
Exam trap: Redundancy != High Availability. Ridondanza = pezzi di ricambio disponibili. HA = sistema che non si interrompe mai, failover automatico. L'HA implica ridondanza, ma la ridondanza non implica HA.
High availability across zones: i nodi sono in zone geografiche diverse. Se un nodo cade, gli altri assorbono il carico — nessun singolo punto di failure.
Resilience vs Availability: concetti distinti ma collegati. Availability = il servizio e' su. Resilience = il servizio regge anche sotto stress (attacchi, guasti). Un sistema puo' essere disponibile ma non resiliente (regge finche' tutto va bene, crolla sotto attacco).
Segmentazione cloud: le reti cloud supportano VPC (Virtual Private Cloud), subnet, security group — equivalenti cloud di VLAN e screened subnet. Fondamentale per isolare dati sensibili dal resto dell'infrastruttura.
Exam tip: le sei considerazioni sono un elenco da memorizzare. La trap e' confondere Availability (sistema su/giu') con Resilience (sistema regge lo stress) e Scalability (cresce col carico) con Responsiveness (velocita' di risposta). Sono quattro concetti distinti.
On-Premises vs Off-Premises#
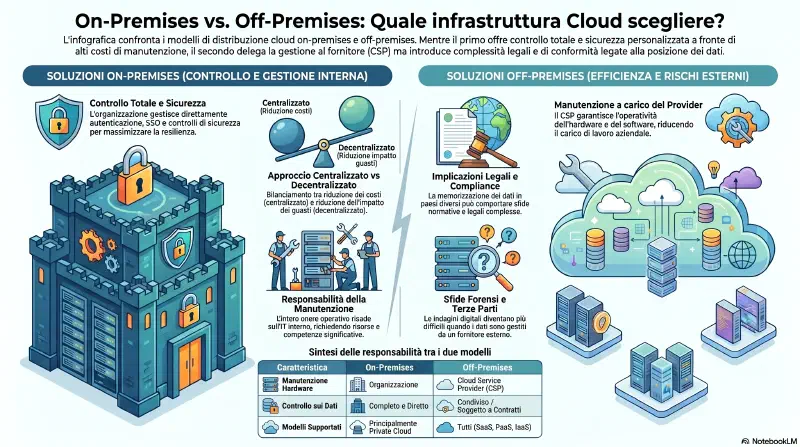
| On-Premises | Off-Premises | |
|---|---|---|
| Hardware | Dentro la sede dell'organizzazione | In un data center del CSP |
| Deployment models supportati | Solo Private Cloud | Qualsiasi (Public, Private, Community, Hybrid) |
| Public Cloud | Mai | Sempre |
| Manutenzione | L'organizzazione | Il CSP |
| Controllo sui dati | Totale | Limitato |
On-Premises
L'organizzazione mantiene controllo completo su tutte le risorse e sui dati. Gestisce autonomamente autenticazione e autorizzazione — piu' semplice implementare SSO (Single Sign-On) senza account separati per le risorse cloud.
Svantaggio: l'organizzazione e' responsabile di tutta la manutenzione. Per chi non ha un grande IT department, mantenere un'infrastruttura cloud on-premises puo' essere insostenibile.
Scelta architetturale on-premises:
| Approccio | Caratteristica | Vantaggio |
|---|---|---|
| Centralizzato | Equipment in uno o pochi data center grandi | Costi ridotti, gestione semplificata |
| Decentralizzato | Equipment distribuito in molti data center piccoli | Riduce l'impatto del fallimento di una singola sede |
Centralized management console — single pane of glass
Quando l'infrastruttura e' distribuita (piu' sedi, piu' cloud provider, piu' OS), la sfida di sicurezza diventa: come monitoro tutto da un punto solo?
La risposta e' una console di gestione centralizzata — un unico pannello da cui vedere ogni utente, ogni dispositivo, ogni applicazione. Fornisce:
- Alert consolidati da tutte le sorgenti
- Analisi centralizzata dei log (un solo punto di ricerca)
- Processo globale di patch e manutenzione
Tradeoff critico: questa console e' anche un Single Point of Failure (SPOF). Se il sistema cade, l'organizzazione perde completamente la visibilita' sulla propria postura di sicurezza. Piu' l'organizzazione cresce, piu' la console lavora — richiede piu' storage per i log, piu' CPU per gli alert.
Exam keyword: "single pane of glass" = console centralizzata di security management. Vantaggio: visibilita' completa. Svantaggio: SPOF (Single Point of Failure).
Off-Premises
Il CSP si occupa della manutenzione. Anche in IaaS — il modello con piu' responsabilita' sul cliente — il CSP garantisce comunque che l'hardware sia operativo.
Due rischi specifici off-premises:
Data residency: l'organizzazione potrebbe non sapere dove sono fisicamente i dati. Se sono in un altro paese, si applicano le leggi di quel paese — implicazioni legali e di compliance. Soluzione contrattuale: richiedere al CSP di conservare i dati in un unico paese.
Digital forensics: gia' difficile on-premises, diventa piu' complessa con infrastruttura cloud. Il CSP e' una terza parte — ogni volta che un'organizzazione contrae con un cloud provider, quel provider diventa un third-party source. Vale anche quando il CSP conserva solo dati o fornisce un singolo servizio.
Exam tip: on-premises = controllo totale, manutenzione a tuo carico, solo private cloud. Off-premises = CSP gestisce l'hardware, public cloud e' sempre off-premises. Rischi off-premises: data residency (leggi straniere) e forensics complicata (third-party source).
Hardening Cloud Environments#
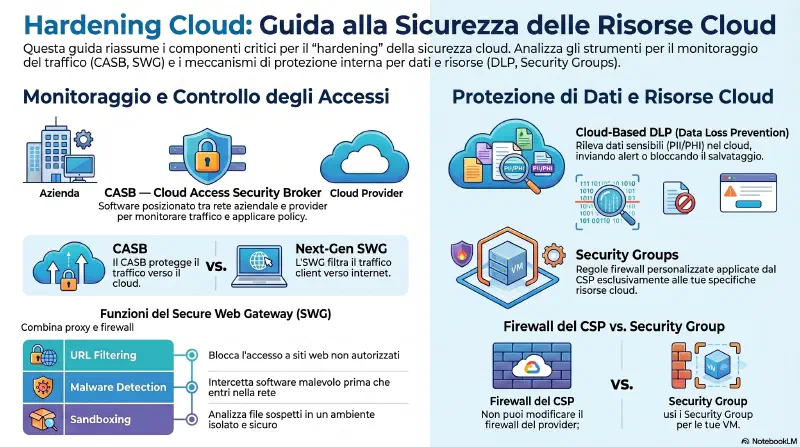
mindmap
root((Hardening Cloud))
CASB
Tra org e cloud provider
Applica policy
Blocca shadow IT
Cloud DLP
Rileva PII PHI nel cloud
Alert blocco quarantena
SWG Next-Gen
Proxy + firewall stateless
URL filtering
Malware detection
Sandboxing
Security Groups
Regole firewall tue risorse
Non modifica CSP firewall
IaC
Terraform CloudFormation
Virtual objects via codice
Riusabile automazione
SDN
Data Plane forward blocca
Control Plane path routing
SD-WAN reti geografiche
Edge e Fog Computing
Edge sul dispositivo
Latenza zero
Fog nodo locale
Coordina piu sensori
Problema latenza cloud
CASB — Cloud Access Security Broker#
I CSP offrono protezioni native, ma alcune organizzazioni vogliono controllo aggiuntivo e cercano soluzioni di terze parti. Il CASB e' una di queste.
Un CASB e' un software o servizio deployato tra la rete dell'organizzazione e il cloud provider. Monitora il traffico e applica le policy di sicurezza. Tutto cio' che e' accessibile via internet e' un attack vector — incluse le risorse cloud. Il CASB mitiga questi rischi applicando le policy in modo coerente su tutti i cloud service provider usati dall'organizzazione.
Utenti aziendali
|
[CASB] ← monitora traffico, applica policy
|
Cloud providerCloud-Based DLP#
E' comune per il personale aziendale salvare dati nel cloud per accedervi da qualsiasi luogo e dispositivo. Le soluzioni DLP cloud permettono di implementare policy per i dati conservati nel cloud.
Esempio Gibson: un'organizzazione configura una policy per rilevare PII (Personally Identifiable Information) o PHI (Protected Health Information) salvati nel cloud. Dopo il rilevamento, la policy DLP puo' eseguire una o piu' azioni:
- Inviare un alert al security administrator
- Bloccare i tentativi di salvare il dato nel cloud
- Mettere in quarantena il dato
Exam keyword: "cloud-based DLP" = applica policy di sicurezza per i dati nel cloud. Esempio tipico: garantire che i PII siano cifrati.
Next-Generation Secure Web Gateway (SWG)#
Client A ──┐
Client B ──┤──→ [ SWG ] ──→ Internet
Client C ──┘ │
↓
URL filtering
Malware detection
DLP
Sandboxing
(blocca / lascia passare)Un SWG di nuova generazione e' la combinazione di un proxy server e un firewall stateless. E' tipicamente un servizio cloud-based, ma puo' essere un appliance on-site. I client sono configurati per accedere a tutte le risorse internet tramite l'SWG.
Servizi forniti dall'SWG:
| Servizio | Espansione | Cosa fa |
|---|---|---|
| URL filtering | Filtro URL | Blocca l'accesso a siti non autorizzati |
| Packet filtering | Filtro pacchetti | Rileva e blocca traffico malevolo |
| Malware detection | Rilevamento malware | Blocca malware prima che entri nella rete |
| Network-based DLP | Data Loss Prevention | Previene esfiltrazione di dati |
| Sandboxing | Sandboxing | Analizza file sospetti in ambiente isolato |
Exam tip: CASB = tra rete aziendale e cloud provider, monitora traffico e applica policy. SWG = proxy per il traffico client verso internet, filtra URL e scansiona malware. Sono complementari — CASB guarda il traffico verso il cloud, SWG guarda il traffico verso internet in generale.
Cloud Firewall e Security Groups#
I CSP hanno firewall sofisticati che proteggono le loro reti. Questi firewall filtrano il traffico verso le risorse cloud di tutti i clienti — ma il CSP non permette di modificarli direttamente. Motivo: le tue regole potrebbero compromettere la sicurezza degli altri clienti sulla stessa infrastruttura.
I Security Groups risolvono il problema: ti permettono di scrivere regole firewall che si applicano solo alle tue risorse. Il CSP usa il proprio firewall per applicare le regole che hai definito nel tuo security group, senza darti accesso diretto al firewall.
CSP Firewall (non modificabile direttamente)
|
Security Group ← tue regole, solo per le tue risorse
|
Le tue VM / risorse cloudEsempio pratico: su Hetzner, la voce "Firewall" nella console non e' il firewall Hetzner — e' il tuo Security Group. Scrivi le regole li', Hetzner le applica solo sulle tue VM.
I security group vanno gestiti con attenzione: un errore non colpisce gli altri clienti, ma puo' compromettere completamente la sicurezza dei tuoi sistemi.
Exam tip: non puoi modificare il firewall del CSP direttamente. Usi i Security Groups per definire regole che il CSP applica solo per le tue risorse.
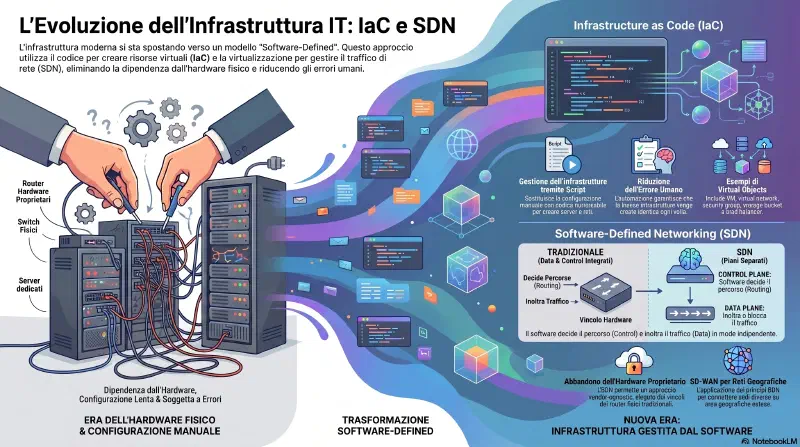
Infrastructure as Code (IaC)#

Virtual objects = tutto quello che esiste nell'infrastruttura cloud/virtualizzata che non è hardware fisico.
Esempi concreti:
- VM (server virtuale)
- Virtual network (rete virtuale)
- Security Group (firewall virtuale)
- Storage bucket
- Load balancer virtuale
- Subnet virtuale
Gli amministratori preferiscono questo approccio perche' produce codice riusabile e facilita l'automazione: lo stesso script crea la stessa infrastruttura ogni volta, senza errori umani.
Esempi di tool IaC: Terraform, AWS CloudFormation, Ansible.
Esempio concreto — creare la tua VPS Hetzner con Terraform:
# main.tf
resource "hcloud_server" "web" {
name = "mustache-web"
server_type = "cx22"
image = "ubuntu-24.04"
location = "nbg1"
}
resource "hcloud_firewall" "web_fw" {
name = "mustache-firewall"
rule {
direction = "in"
protocol = "tcp"
port = "443"
source_ips = ["0.0.0.0/0"]
}
}Esegui terraform apply e Hetzner crea il server + il firewall in automatico. Vuoi rifare tutto da capo? terraform destroy + terraform apply. Stesso risultato ogni volta — nessun click, nessun errore umano.
Exam tip: IaC = codice per creare virtual objects (VM, reti). Vantaggi: riusabilita' e automazione.
Software-Defined Networking (SDN)#
L'SDN separa due piani distinti nella rete:
| Piano | Espansione | Cosa fa | Tecnologia tradizionale |
|---|---|---|---|
| Data plane | Piano dati | Decide se forwardare o bloccare il traffico | Regole ACL su router hardware (proprietario) |
| Control plane | Piano di controllo | Determina il percorso migliore da prendere | Protocolli di routing (OSPF, BGP) |
Nei router hardware tradizionali, entrambi i piani girano sullo stesso dispositivo fisico e sono proprietari — legati a quel vendor specifico. L'SDN implementa il data plane via software e virtualizzazione, permettendo di abbandonare l'hardware proprietario.
Il control plane usa gli stessi protocolli di routing (OSPF, BGP): i router li usano per condividere informazioni e costruire una mappa della rete. L'SDN puo' usare gli stessi protocolli, ma senza hardware fisico.
SD-WAN — Software-Defined Wide Area Network: quando l'SDN opera su reti geograficamente distribuite (WAN) per connettere sedi diverse, prende il nome di SD-WAN.
Rete tradizionale: SDN:
Router fisico Software controller
[data plane] [control plane]
[control plane] |
→ proprietario ↓
→ vendor lock-in Virtual switches
[data plane in software]
→ vendor-agnosticExam tip: SDN = data plane e control plane separati e implementati via software. Data plane = forward/block (ACL). Control plane = path determination (OSPF, BGP). SD-WAN = SDN applicato alle WAN per connettere sedi remote.
Edge Computing e Fog Computing#
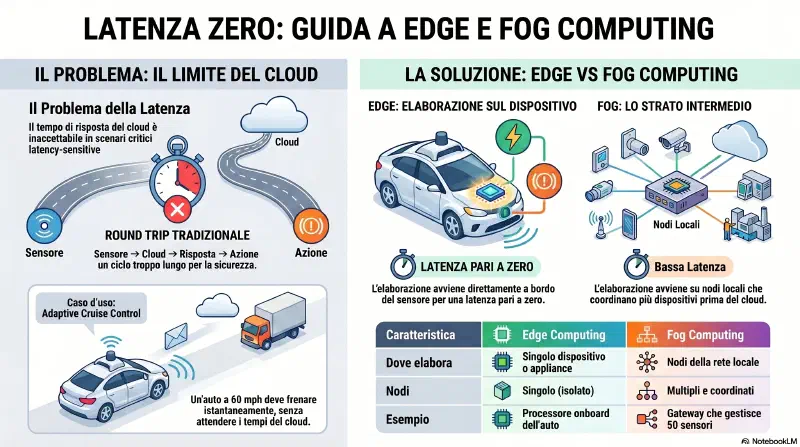
Il concetto chiave e' la latenza — il tempo che passa tra l'invio di un dato e la ricezione della risposta. Edge e fog computing esistono per eliminarla quando e' inaccettabile.
Il problema del cloud tradizionale:
Sensore → cloud (elaborazione) → risposta → azione
↑
round trip: troppo lento in scenari criticiEsempio Gibson — adaptive cruise control: un'auto a 60 mph rileva traffico in rallentamento. Se i dati dei sensori vanno al cloud per essere elaborati, l'auto potrebbe crashare prima di ricevere la risposta. Il round trip e' troppo lento.
Edge computing:
L'elaborazione avviene sul dispositivo stesso o su un appliance fisicamente vicino. Zero round trip verso il cloud — latenza eliminata.
Sensore auto → processore a bordo → frena subitoFog computing:
Quasi identico all'edge, ma l'elaborazione avviene su un nodo della rete locale vicino ai dispositivi — non sul dispositivo stesso. La fog network puo' avere nodi multipli che rilevano ed elaborano dati insieme.
| Edge | Fog | |
|---|---|---|
| Dove elabora | Sul singolo dispositivo o appliance | Su nodo/i della rete locale |
| Nodi | Singolo | Multipli, si coordinano |
| Esempio | Processore onboard dell'auto | Gateway locale che coordina 50 sensori |
La "fog" e' lo strato intermedio tra i dispositivi e il cloud — elabora localmente prima di passare i dati aggregati al cloud centrale.
Exam tip: edge = singolo dispositivo, latenza zero. Fog = rete locale con nodi multipli. Entrambi risolvono la latenza del cloud tradizionale. Keyword da ricordare: "latency-sensitive".
Mobile Devices#
mindmap
root((Mobile Devices))
Deployment Models
Corporate-owned controllo totale
COPE org compra uso personale
BYOD dipendente porta
CYOD dipendente sceglie da lista
Trappola chi compra
Connection Methods
Cellular LTE 5G
Wi-Fi
Bluetooth PAN
Tethering hotspot
Wi-Fi Direct peer-to-peer
MDM e UEM
App management allow list
Full device encryption
Storage segmentation
Containerization BYOD
Remote wipe
Geofencing confine virtuale
Geotagging rischio privacy
Context-aware auth
Hardening Mobile
Jailbreaking iOS restrizioni
Rooting Android accesso root
Sideloading APK Unknown Sources
OTA firmware update
NAC blocca non conformi
I dispositivi mobili rappresentano sfide significative per le organizzazioni. Le domande chiave sono: i dipendenti possono connettere i loro dispositivi alla rete? Se si', come si gestiscono sicurezza, monitoraggio e policy?
Cosa e' un dispositivo mobile#
Nel contesto Security+: smartphone o tablet. NIST SP 800-124 aggiunge caratteristiche specifiche:
Caratteristiche obbligatorie (per rientrare nella definizione NIST):
- Almeno un'interfaccia di rete wireless
- Storage locale
- Sistema operativo
- Possibilita' di installare applicazioni aggiuntive
Caratteristiche opzionali tipiche: Bluetooth, NFC, accesso cellulare per voce, GPS, fotocamera digitale, videoregistratore, microfono, trasferimento dati ad altri sistemi.
Esclusi dalla definizione NIST: laptop e desktop (mancano GPS e sensori di movimento come accelerometro e giroscopio), telefoni base, fotocamere digitali, dispositivi IoT (non hanno OS o hanno OS limitato).
Mobile Device Deployment Models#
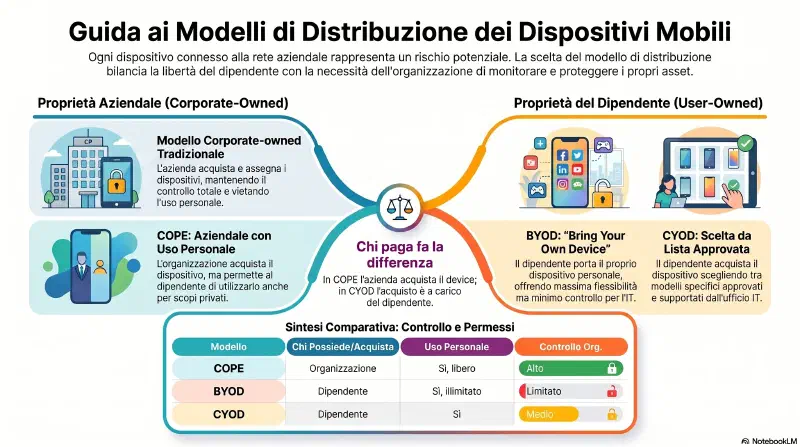
| Modello | Espansione | Chi possiede | Uso personale | Controllo org |
|---|---|---|---|---|
| Corporate-owned | — | Organizzazione | No | Totale |
| COPE | Corporate-Owned, Personally Enabled | Organizzazione | Si', libero | Alto |
| BYOD | Bring Your Own Device | Dipendente | Si', illimitato | Limitato |
| CYOD | Choose Your Own Device | Dipendente | Si' | Medio (lista approvata) |
Corporate-owned: modello tradizionale. L'organizzazione acquista i dispositivi e li assegna ai dipendenti.
COPE — Corporate-Owned, Personally Enabled: l'organizzazione acquista il dispositivo, ma il dipendente lo usa come se fosse suo — attivita' personali incluse. Il fatto che l'organizzazione possieda il dispositivo facilita la gestione.
Come con BYOD, il device COPE e' diviso in partizioni: una per i dati aziendali, una per i dati personali. L'amministratore puo' cancellare la partizione aziendale in qualsiasi momento senza toccare i dati personali — utile in caso di licenziamento o smarrimento del device.
BYOD — Bring Your Own Device: i dipendenti portano i propri dispositivi e li connettono alla rete. Il dipendente sceglie e supporta il device, ma deve rispettare la BYOD policy. Tra i professionisti IT e' ironicamente chiamato "bring your own disaster" — l'IT finisce per dover supportare qualsiasi dispositivo esistente.
Policy cambio device: quando un dipendente vende o rottama il vecchio telefono, i dati aziendali devono essere cancellati prima della cessione. L'MDM gestisce questo tramite remote wipe selettivo della partizione aziendale. Il nuovo device va poi registrato nell'MDM prima di poter accedere alle risorse aziendali.
CYOD — Choose Your Own Device: l'organizzazione pubblica una lista di dispositivi approvati. Il dipendente sceglie dalla lista e lo acquista. Soluzione intermedia: l'IT supporta un insieme limitato di device invece di qualsiasi dispositivo.
Exam trap COPE vs CYOD: in COPE l'organizzazione acquista il dispositivo. In CYOD il dipendente acquista dalla lista approvata. La differenza e' chi paga.
Exam tip: BYOD = dipendente porta il suo → massima flessibilita', minimo controllo. COPE = org compra, dipendente usa anche per cose personali → controllo mantenuto. CYOD = dipendente sceglie da lista approvata e compra → controllo sulla tipologia, non sul singolo device.
Connection Methods#
| Metodo | Espansione | Note |
|---|---|---|
| Cellular | LTE / 4G / 5G | Dipende da provider, posizione e dispositivo. Generazioni piu' recenti = piu' velocita' e qualita' voce |
| Wi-Fi | Wireless network interface | Quasi sempre presente. Protocolli in Cap 4 |
| Bluetooth | Personal Area Network | Cuffie wireless, connessione tra smartphone. Attacchi Bluetooth in Cap 4 |
| Tethering | Condivisione connessione | Un dispositivo mobile condivide la sua connessione internet con altri device — es. iPhone come hotspot |
| Wi-Fi Direct | Connessione peer-to-peer | Collega due device direttamente senza passare per un router wireless. Utile per stampare o condividere file |
Rischi Wi-Fi pubblico (coffee shop, hotel, aeroporto)
Le reti Wi-Fi pubbliche spesso non sono cifrate. Un attaccante nella stessa area geografica puo':
- Monitorare il traffico — leggere dati non cifrati in transito
- On-path attack (MITM) — inserirsi tra il tuo device e il router, intercettando e potenzialmente modificando tutto il traffico
- DoS via interferenza — generare interferenza sulle frequenze Wi-Fi per bloccare le connessioni
Vale uguale per laptop e desktop connessi a Wi-Fi pubblico — non solo mobile.
Difesa: VPN su qualsiasi rete non fidata. La VPN cifra tutto il traffico tra il device e il server VPN, rendendo inutile il monitoraggio locale.
Bluetooth — rischi di pairing
Il Bluetooth e' progettato per distanze brevi (PAN — Personal Area Network). Il pairing e' il meccanismo di sicurezza: la prima connessione richiede conferma esplicita. Non accettare pairing da device sconosciuti — un device Bluetooth ostile puo' accedere ai dati sul tuo telefono.
MDM — Mobile Device Management#
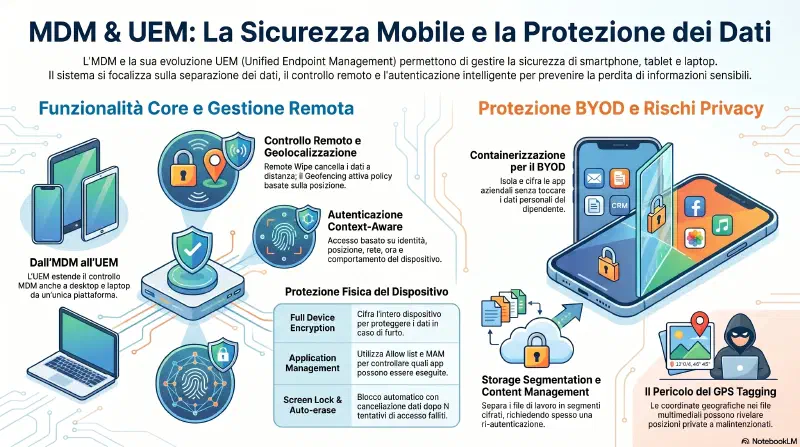
Server MDM — la parte centrale. Riceve i comandi dell'amministratore (installa questa app, fai remote wipe, applica questa policy) e li distribuisce.
Agente MDM — software installato sul device. Riceve i comandi dal server e li esegue localmente. È anche lui che raccoglie informazioni sullo stato del device (patchato? jailbroken? antivirus ok?) e le riporta al server.
Senza agente il server non può fare nulla sul device — è il punto di contatto.
L'unica eccezione è iOS con l'Apple MDM protocol: su iPhone l'agente non è una app separata visibile — è integrato nel sistema operativo. Su Android invece l'agente è spesso un'app installabile.
Tabella delle funzionalita' MDM principali:
| Funzionalita' | Cosa fa | Keyword esame |
|---|---|---|
| Application management | Allow list per controllare quali app possono girare. MAM (Mobile Application Management) e' il sottoinsieme focalizzato solo sulle app | Allow list, MAM |
| Full device encryption | Cifra tutto il dispositivo — protegge dati se il device e' perso o rubato | FDE mobile |
| Storage segmentation | Isola i dati aziendali in uno spazio separato (es. storage esterno o segmento cifrato) dai dati personali | Segmentazione storage |
| Content management | Garantisce che i contenuti aziendali finiscano nel segmento cifrato. Puo' richiedere ri-autenticazione per accedere ai dati aziendali | Content management |
| Containerization | Isola l'app aziendale in un container cifrato senza cifrare l'intero device — utile in BYOD | Container, BYOD |
| Passwords e PIN | Policy password simili ai desktop. Alcuni device supportano solo PIN | PIN policy |
| Biometrics | Riconoscimento facciale, impronta digitale come alternativa a password/PIN | Biometrics auth |
| Screen lock | Blocco automatico dopo N minuti. Spesso combinato con auto-erase dopo X tentativi falliti | Screen lock, auto-erase |
| Remote wipe | Segnale remoto che cancella tutti i dati (inclusi dati cached come password bancarie) | Remote wipe |
| Geolocation | GPS per localizzare il dispositivo — utile se perso o rubato | GPS, geolocation |
| Geofencing | Confine virtuale geografico. Le app possono attivarsi/disattivarsi in base alla posizione del device. Esempio: fotocamera disabilitata dentro il campus aziendale, riabilitata automaticamente all'uscita | Geofencing |
| GPS tagging | Aggiunge coordinate geografiche ai file (foto, video). Rischio privacy: chi vede le foto sa dove sono state scattate | Geotagging |
| Context-aware authentication | Autenticazione multi-elemento: identita' utente + geolocation + geofence + rete + comportamento + ora + tipo di device | Context-aware auth |
| Push notifications | Messaggi inviati alle app anche con screen lock attivo. MDM li usa per notificare problemi di compliance | Push notifications |
Containerization in BYOD — perche' e' il caso d'uso principale:
Con BYOD l'organizzazione non puo' cifrare l'intero device personale del dipendente. Il container risolve il problema: isola e cifra solo la parte aziendale, senza toccare i dati personali.
Device BYOD (dipendente)
├── [CONTAINER CIFRATO] ← app e dati aziendali, gestito da MDM
│ Email aziendale
│ VPN
│ File aziendali
└── Resto del device ← personale, non toccato dall'org
Instagram
Foto
WhatsAppGPS tagging — il rischio che Gibson evidenzia:
Lisa posta regolarmente foto di casa con GPS tagging attivo. I ladri identificano il suo indirizzo. Quando posta foto da una location di vacanza, i ladri sanno che la casa e' vuota.
Remote wipe e autorita' per modello:
| Modello | Wipe completo | Wipe selettivo (solo dati aziendali) |
|---|---|---|
| COPE | Si' — l'org possiede il device | Si' |
| BYOD | No* — e' proprieta' del dipendente | Si' — autorizzato dalla policy MDM firmata all'enrollment |
| CYOD | No* — e' proprieta' del dipendente | Si' — autorizzato dalla policy MDM firmata all'enrollment |
*Salvo che la policy firmata preveda esplicitamente il wipe completo (es. in caso di smarrimento o furto).
In BYOD e CYOD l'autorizzazione al wipe selettivo non viene chiesta al momento — e' stata data in anticipo firmando la policy di enrollment MDM.
Exam trap: "Can the organization remotely wipe a BYOD device?" — risposta corretta: solo i dati aziendali (wipe selettivo), non il device intero. Il wipe completo richiederebbe proprieta' del device (COPE) o consenso esplicito preventivo nella policy.
Exam keywords da ricordare: remote wipe = cancella tutto da remoto. Geolocation = GPS per trovare il device. Geofencing = confine virtuale geografico. GPS tagging = coordinate geografiche nei file. Context-aware authentication = autenticazione multi-elemento (identita' + posizione + device + comportamento).
Exam tip: containerization e' la soluzione MDM specifica per BYOD — permette di proteggere i dati aziendali senza cifrare l'intero device personale. UEM = MDM esteso a tutti gli endpoint (desktop inclusi).
Hardening Mobile Devices#
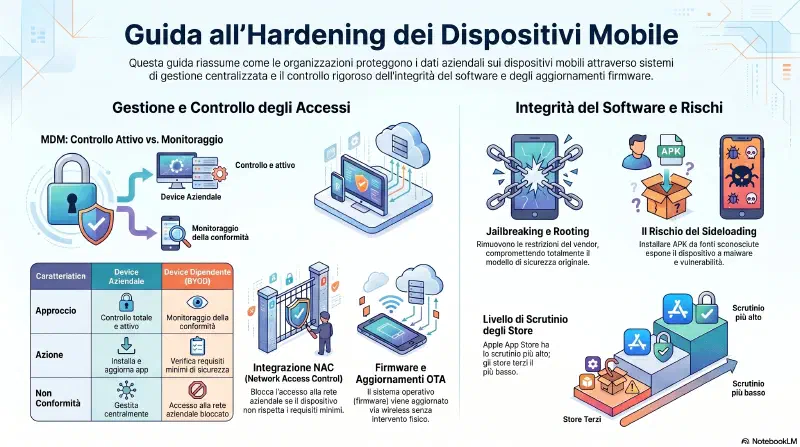
MDM e proprieta' del device — due approcci diversi
L'MDM gestisce i device in modo diverso in base a chi li possiede:
| Device aziendale | Device del dipendente (BYOD) | |
|---|---|---|
| Approccio | Controllo attivo | Monitoraggio compliance |
| Cosa fa | Installa app, le aggiorna, gestisce tutto | Controlla se il device rispetta i requisiti minimi |
| Se non conforme | N/A | Blocca l'accesso alla rete aziendale tramite NAC |
NAC (Network Access Control): quando l'MDM rileva un device BYOD non conforme (non patchato, antivirus non aggiornato), si integra con il NAC per impedire la connessione alla rete aziendale. Il telefono continua a funzionare su rete cellulare o Wi-Fi personale — ma non accede al Wi-Fi aziendale, VPN o risorse interne finche' non soddisfa i requisiti.
Device BYOD non patchato
|
MDM → "non conforme"
|
NAC → blocca accesso rete aziendale
|
niente Wi-Fi / VPN aziendali — finche' non si aggiornaUnauthorized Software
Le organizzazioni vogliono che gli utenti installino app solo da fonti approvate.
| Store | Piattaforma | Livello di scrutinio |
|---|---|---|
| Apple App Store | iOS / iPadOS | Alto — Apple testa attivamente per malware, banna i developer che distribuiscono malware |
| Google Play | Android | Alto — ma meno restrittivo di Apple |
| Third-party app store | Entrambi | Basso — nessun livello di scrutinio equivalente. Rischio maggiore |
Apple rende molto difficile installare app da store terzi. Su Android e' relativamente facile.
Jailbreaking (iOS): rimuove tutte le restrizioni software da un device Apple. Dopo il jailbreak l'utente puo' installare software da qualsiasi fonte terza. Rompe il modello di sicurezza del vendor.
Rooting (Android): modifica il device per dare all'utente accesso root (amministratore completo). Equivalente del jailbreaking su Android.
Entrambi introducono rischi e vulnerabilita'. E' comune che l'MDM blocchi completamente l'accesso alla rete se rileva un device rootato o jailbroken.
Firmware e OTA updates
I dispositivi mobili conservano il sistema operativo in memoria integrata — tipicamente flash memory, che mantiene i dati anche senza alimentazione. Poiche' il SO e' software e la memoria e' hardware, questa combinazione si chiama firmware.
Gli aggiornamenti del SO sovrascrivono il firmware tramite OTA (Over-The-Air) updates — wireless, senza collegare il device a un computer.
Quando Apple rilascia iOS 18, l'aggiornamento arriva direttamente sul tuo iPhone via Wi-Fi o dati — lo scarichi, lo installi, il telefono si riavvia con il nuovo SO.
Quello che sta succedendo sotto: il nuovo iOS sovrascrive il firmware nella flash memory integrata del telefono. Il vecchio firmware viene rimpiazzato.
"Over-the-Air" significa semplicemente che arriva via aria — wireless. Contrapposto al vecchio metodo di collegare il telefono al Mac con il cavo USB e aggiornare tramite iTunes.
Stesso concetto dei router moderni: aggiornamento firmware disponibile → lo scarichi dalla console web → sovrascrive il chip. Nessun cavo, nessun intervento fisico.
Custom firmware: e' possibile sovrascrivere il firmware con una versione custom. Usato come metodo alternativo di rooting su Android — processo complesso e rischioso. Alcune persone scaricano immagini e le copiano sul device per sovrascrivere il firmware originale.
Sideloading: installare applicazioni su Android copiando un file APK (Application Package Kit) direttamente sul device e attivandolo. Richiede di abilitare "Unknown Sources" nelle impostazioni — il che indebolisce significativamente la sicurezza. Utile per developer che testano app, rischioso quando si installano app da terze parti.
Jailbreaking = rimozione restrizioni su iOS. Rooting = accesso root su Android. Entrambi → MDM blocca l'accesso alla rete. Sideloading = installare APK Android fuori dal Play Store, richiede "Unknown Sources".
Exam tip: firmware = OS mobile su flash memory (software + hardware insieme). OTA = aggiornamento firmware wireless. Custom firmware = metodo di rooting alternativo. NAC + MDM = se BYOD non e' conforme, niente rete aziendale.
Embedded Systems#
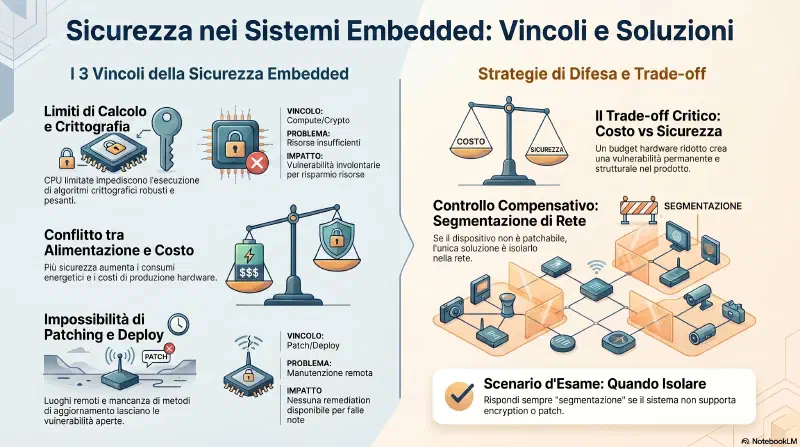
mindmap
root((Embedded Systems))
Funzione Dedicata
MFP stampante
Router ECU ATM PLC
IoT
Facility sanita automotive
NISTIR 8228
Superficie attacco enorme
ICS e SCADA
ICS controlla fisico
PLC Programmable Logic
SCADA supervisiona ICS
CIA invertita Availability prima
VLAN isolata NIPS
Stuxnet Colonial Pipeline
Componenti
SoC tutto in un chip
Compatto power-efficient
RTOS timing deterministico
Medical automotive
Vincoli 6
Compute limitato
Crypto limitata
Power batteria
Deployment remoto
Cost sicurezza tagliata
No-Patch impossibile
Difesa
Segmentazione di rete
Compensating controls
No patch applicare isolare
Un sistema embedded e' un computer dentro un oggetto che esiste per fare una funzione specifica.
Un Mac e' general-purpose: ci puoi fare qualsiasi cosa. Un sistema embedded ha CPU, OS e applicazioni come il Mac — ma non e' progettato per usi generici. E' costruito per fare solo quello.
Esempi:
| Dispositivo | Funzione dedicata | Ha CPU + OS? |
|---|---|---|
| Stampante Wi-Fi MFP | Stampare, scansionare, copiare, inviare fax | Si |
| Router di casa | Instradare traffico di rete | Si |
| Termostato smart | Gestire la temperatura | Si |
| Centralina auto (ECU) | Controllare il motore | Si |
| Bancomat (ATM) | Operazioni bancarie | Si |
Esempio Gibson — stampante MFP: ha un web server interno accessibile via Wi-Fi per la configurazione, gestisce lavori di stampa, scansione, copia, fax e invio email. E' un computer completo, ma dedicato solo a quelle funzioni.
Exam tip: embedded system = computer dedicato a una funzione specifica. Ha CPU, OS e applicazioni come un PC tradizionale — ma non e' general-purpose. Keyword: "dedicated function".
IoT — Internet of Things#
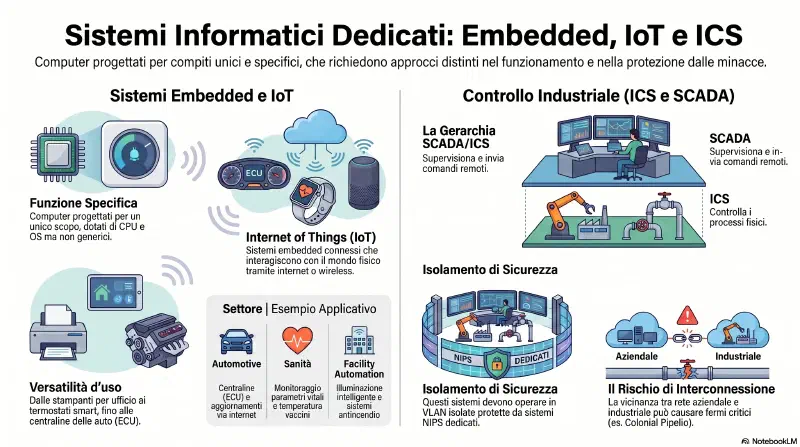
NISTIR 8228 (NIST) precisa che lo scope completo dell'IoT non e' definito con precisione — le tecnologie coprono settori molto diversi: sanita', trasporti, sicurezza domestica.
Esempi per settore:
| Settore | Esempi IoT |
|---|---|
| Facility automation | Illuminazione motion-controlled, telecamere di sicurezza, sistemi rilevamento e soppressione incendi |
| Sanita' | Monitoraggio temperatura vaccini, rilevamento parametri vitali pazienti |
| Automotive | Sistemi embedded per il controllo dell'auto, aggiornamenti OTA — i produttori potrebbero rendere tutti i sistemi embedded accessibili via internet |
| Aeronautica | Tracciamento manutenzione e performance di ogni parte in movimento dell'aereo |
| UAV | Hobbyist: foto remote. Militare: ricognizione e sistemi d'arma con embedded systems sofisticati |
| Smart meters | Rete elettrica — monitoraggio e registrazione remota del consumo energetico, analytics a server centralizzati |
UAV — Unmanned Aerial Vehicle: veicolo aereo senza pilota a bordo. I droni hobbyist usano embedded systems semplici. I droni militari hanno sistemi embedded sofisticati per missioni di ricognizione e armamento.
I produttori di automobili potrebbero integrare tutti i sistemi embedded in un'unica architettura accessibile via internet — rendendo ogni sistema raggiungibile dagli attaccanti. Superficie di attacco enorme su un oggetto fisico in movimento.
ICS e SCADA#
ICS — Industrial Control System: sistemi all'interno di grandi impianti come centrali elettriche o impianti di trattamento acque. Controllano processi fisici industriali.
SCADA — Supervisory Control and Data Acquisition: sistema che controlla un ICS monitorandolo e inviandogli comandi. E' il "cervello" sopra l'ICS.
Idealmente questi sistemi vivono in reti isolate senza accesso a internet — il caso estremo e' l'air-gap: nessuna connessione fisica con la rete aziendale o internet. Un sistema air-gapped non e' raggiungibile da remoto per definizione. In pratica i sistemi SCADA sono spesso collegati alla rete aziendale ma isolati in una VLAN dedicata protetta da un NIPS (Network Intrusion Prevention System) che blocca il traffico indesiderato.
Internet
|
[Firewall]
|
Rete aziendale
|
[NIPS] ← blocca traffico non autorizzato verso ICS/SCADA
|
VLAN isolata
|
ICS / SCADA ← non raggiungibile direttamente da internetFiume
|
Diga (valvole fisiche)
|
PLC ← ICS: controlla apertura/chiusura valvole
PLC ← ICS: controlla velocità turbine
PLC ← ICS: controlla generatori
|
SCADA server ← supervisiona tutto, manda comandi ai PLC
|
Sala controllo ← operatori vedono grafici, intervengono se necessario
ICS = i PLC fisici che aprono valvole, regolano turbine, controllano generatori. Ogni PLC controlla un pezzo del processo fisico.
SCADA = il sistema sopra che raccoglie dati da tutti i PLC, li mostra agli operatori su dashboard, e permette di mandare comandi da remoto ("riduci velocità turbina 3").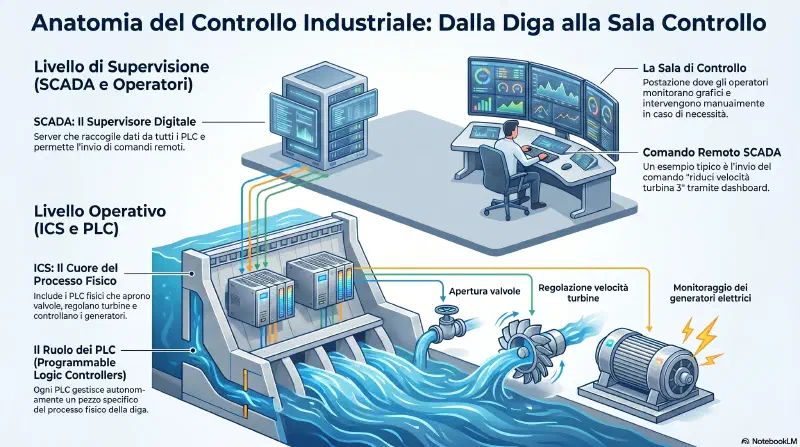
Caso reale — Colonial Pipeline 2021: attacco ransomware che ha colpito i sistemi IT della società. Per paura che il ransomware raggiungesse i sistemi SCADA che controllano l'oleodotto, hanno spento tutto preventivamente. Risultato: 6 giorni di interruzione, carburante razionato sulla East Coast USA. L'attacco non ha mai toccato i sistemi SCADA — ma la vicinanza tra rete IT e rete SCADA era abbastanza preoccupante da giustificare lo spegnimento.
Questo è esattamente perché Gibson dice che ICS/SCADA dovrebbero stare in reti isolate.
Usi comuni di ICS e SCADA:
| Settore | Espansione | Esempio |
|---|---|---|
| Manufacturing | Produzione industriale | Monitoraggio ogni fase di produzione, alert anomalie in real-time, regolazione automatica processi |
| Facilities | Gestione impianti | Temperatura e umidita' in edifici, fasi di trattamento acque |
| Energy | Energia | Raffinerie oil & gas, generazione elettrica |
| Logistics | Logistica | Monitoraggio processi in magazzini e centri di spedizione |
Exam keyword: SCADA controlla un ICS tramite monitoraggio e comandi. ICS = sistema di controllo industriale (centrale elettrica, impianto idrico). Protezione: VLAN isolata + NIPS. Caso studio classico: Stuxnet (2010) — malware che ha sabotato i PLC Siemens delle centrifughe di arricchimento uranio iraniane modificandone la velocita' mentre i monitor mostravano tutto normale.
Exam tip: ICS/SCADA hanno la CIA triad invertita rispetto all'IT classico — Availability prima di tutto. Un sistema di controllo di una centrale che va offline causa danni fisici immediati. Le patch si rimandano finche' non c'e' una maintenance window — mesi o anni. Compensating controls (VLAN, NIPS, monitoring) invece di patch immediate.
Embedded Systems Components#
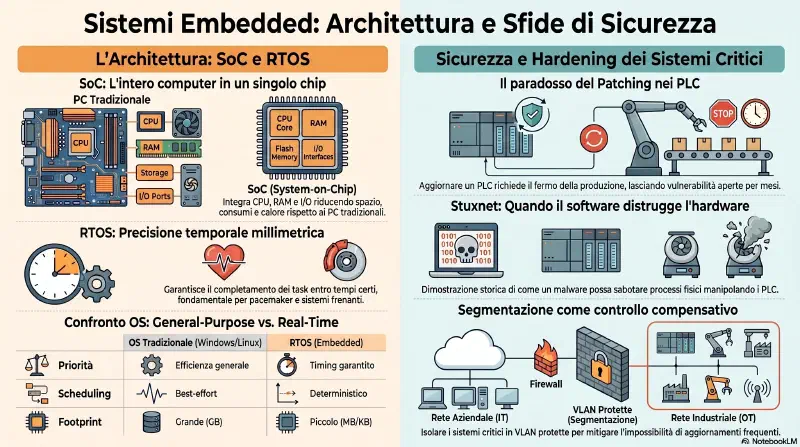
SoC — System-on-Chip
Un SoC integra in un singolo chip tutto quello che in un PC normale occupa una scheda madre intera: processore, memoria, interfacce I/O e altri componenti. Questa integrazione rende i sistemi embedded compatti ed efficienti dal punto di vista energetico, mantenendo la potenza di calcolo necessaria per la funzione specifica.
Gli SoC sono spesso customizzati per l'applicazione specifica — progettati e costruiti appositamente per quel sistema embedded, non chip generici riutilizzabili ovunque.
Esempio: Prima dell'SoC ogni componente era un chip separato sulla scheda madre:
CPU separata RAM separata GPU separata Controller I/O separato Modem separato
Ogni chip occupa spazio fisico, consuma corrente, genera calore, e deve comunicare con gli altri tramite tracce sulla scheda madre — quella comunicazione ha un costo in tempo e energia.
Con l'SoC tutto è sullo stesso chip di silicio:
- Meno spazio → entra in un telefono sottile
- Meno consumi → batteria dura di più
- Comunicazione interna più veloce → performance migliori
- Meno componenti → meno cose che si rompono
Il tuo Mac Intel di qualche anno fa aveva ancora CPU, RAM e GPU separati. Il passaggio ad Apple Silicon (M1/M2/M3) è stato esattamente questo: tutto su un SoC. Risultato: prestazioni più alte, calore ridotto, batteria raddoppiata.
RTOS — Real-Time Operating System
Un OS specializzato per sistemi embedded che richiedono timing preciso e comportamento deterministico. La caratteristica chiave: il real-time scheduling garantisce che certi task vengano completati entro un timeframe specifico.
Questo e' critico dove il timing e' una questione di sicurezza fisica:
- Dispositivi medici: il pacemaker deve erogare l'impulso entro millisecondi precisi
- Sistemi automotive: il sistema frenante deve rispondere entro tempi garantiti
- Controllo industriale: un PLC che manca un ciclo di controllo puo' causare danni fisici
L'RTOS e' anche progettato per essere leggero: piccolo footprint di memoria, basso overhead di processing — adatto a hardware con risorse limitate.
| OS tradizionale (Linux, Windows) | RTOS | |
|---|---|---|
| Priorita' | Efficienza generale | Timing garantito |
| Scheduling | Best-effort | Deterministico |
| Footprint | Grande | Piccolo |
| Uso | PC, server, mobile | Embedded, IoT, industriale |
Exam tip: SoC = tutti i componenti del computer su un singolo chip, compatto e power-efficient, spesso customizzato. RTOS = OS per embedded con timing garantito (deterministico) — critico per medical devices e automotive dove il timing e' safety-critical.
Hardening Specialized Systems#
La sfida principale con sistemi embedded, IoT e ICS/SCADA e' tenerli aggiornati con le patch di sicurezza. Due problemi distinti:
Lato vendor: i produttori di sistemi embedded non sono aggressivi nell'identificare vulnerabilita' e creare patch quanto i vendor di software tradizionale. Microsoft e Apple rilasciano patch regolarmente. I vendor di RTOS e sistemi embedded molto meno.
Lato amministratori IT: il patch management e' routine per Windows e Linux. Ma chi controlla e applica gli aggiornamenti dell'RTOS di un PLC o del firmware di una stampante industriale? Spesso nessuno.
PLC — Programmable Logic Controller: computer industriale che controlla un processo fisico eseguendo in loop continuo: leggi sensori → elabora → aziona. Non ha schermo, tastiera o browser. Viene programmato una volta e gira H24 facendo sempre la stessa cosa.
Esempio — catena di imbottigliamento:
Sensore livello bottiglia
|
PLC ← legge il sensore, decide
|
Valvola acqua ← apre/chiude in base alla decisionePerche' patchare un PLC e' difficile: per applicare una patch devi fermare il processo fisico che controlla. In una centrale elettrica o in un impianto di trattamento acque, fermo = blackout o interruzione del servizio. Si aspetta la maintenance window — che puo' essere tra mesi. Nel frattempo la vulnerabilita' resta aperta.
Stuxnet (2010) ha sfruttato esattamente questo: ha modificato la velocita' dei PLC Siemens nelle centrifughe iraniane. I tecnici vedevano tutto normale sui monitor, ma le centrifughe si distruggevano fisicamente.
Il risultato: vulnerabilita' note rimangono aperte per mesi o anni su sistemi che nel frattempo controllano processi fisici critici.
Segmentazione come compensating control
Poiche' e' difficile gestire in modo sicuro questi sistemi con le patch, la risposta principale e' la segmentazione di rete: isolare i sistemi specialized in una rete separata, bloccata e protetta dagli attacchi esterni.
Rete aziendale generale
|
[Firewall / NIPS]
|
Rete segmentata ← embedded, IoT, ICS/SCADA qui
(VLAN isolata) accesso ristretto
monitoraggio strettoLa logica e': se non puoi proteggere il sistema dall'interno (patch difficili o impossibili), costruisci una barriera intorno. Non puoi toccare il firmware del PLC — ma puoi fare in modo che nessuno ci arrivi.
Exam pattern: "embedded/IoT/ICS non si aggiornano facilmente" → la risposta di sicurezza e' sempre segmentazione. Non "applicare patch" (spesso impossibile) ma "isolare in rete separata con accesso controllato".
Exam tip: patch management per sistemi specialized e' problematico per due ragioni — vendor poco reattivi e amministratori IT che non monitorano questi aggiornamenti. Compensating control = segmentazione di rete.
Embedded System Constraints#
I sistemi embedded hanno vincoli strutturali che limitano le opzioni di sicurezza disponibili:
| Vincolo | Problema | Impatto security |
|---|---|---|
| Compute | CPU limitata, non full CPU | Non puo' eseguire algoritmi crittografici pesanti |
| Cryptographic limitations | Potenza di calcolo insufficiente per tutti i protocolli crypto | Se i designer sacrificano la sicurezza per risparmiare risorse, creano vulnerabilita' involontarie |
| Power | Nessuna alimentazione propria — usa il dispositivo host o batterie | Piu' capacita' di calcolo = piu' consumo = batterie da sostituire piu' spesso. Conflitto diretto tra sicurezza e autonomia |
| Ease of deployment | Spesso in luoghi remoti e difficili da raggiungere | Manutenzione e aggiornamenti complessi. RTOS richiede competenze specializzate — costo e tempi di deploy aumentano |
| Cost | Il costo si abbassa sacrificando funzionalita' | La sicurezza e' la prima funzionalita' che viene tagliata. Tensione tra management (vuole risparmiare) e designer (vuole aggiungere feature) |
| Inability to patch | Spesso impossibile patchare — i vendor non sempre includono metodi di aggiornamento, e quando li includono non rilasciano patch tempestivamente | Vulnerabilita' note restano aperte a lungo. Nessun remediation disponibile |
Il vincolo piu' critico per la sicurezza e' l'interazione tra cost e cryptographic limitations: un dispositivo IoT da pochi euro non ha il budget hardware per cifratura robusta. Se il designer sceglie di non cifrare per risparmiare, quella decisione crea una vulnerabilita' permanente nel prodotto.
Exam pattern: scenario con sistema embedded che non puo' essere patchato o non supporta encryption → la risposta e' sempre segmentazione di rete come compensating control. Non "applicare patch" — non e' possibile.
Exam tip: i sei vincoli da ricordare — compute, crypto, power, deployment, cost, inability to patch. Il trade-off cost vs security e' la causa principale delle vulnerabilita' IoT: i vendor tagliano la sicurezza per abbassare il prezzo.
Exam Topic Review — Gibson Cap 5#
Virtualizzazione#
- La virtualizzazione permette a piu' server di girare su un singolo host fisico. Supporta anche i virtual desktop.
- Un VDI (Virtual Desktop Infrastructure) ospita il desktop OS dell'utente su un server. Thin client e dispositivi mobili si connettono al server e accedono al VDI.
- La container virtualization esegue servizi o applicazioni in container isolati. I container usano il kernel del host.
- Gli attacchi VM escape permettono a un attaccante di accedere all'host da una VM guest. Protezione principale: mantenere host e guest aggiornati con le patch correnti.
- Il VM sprawl si verifica quando il personale non gestisce le VM — proliferazione incontrollata.
Secure Systems#
- Gli endpoint sono dispositivi come server, desktop, laptop, mobile, IoT. EDR fornisce monitoraggio continuo. XDR include altri tipi di dispositivi e sistemi.
- Hardening: rendere un OS o applicazione piu' sicuro rispetto all'installazione di default.
- Le pratiche di configuration management aiutano a deployare sistemi con configurazioni sicure.
- Una master image e' un punto di partenza sicuro per i sistemi, creata con template o baseline. Gli integrity measurement tools rilevano quando un sistema devia dalla baseline.
- Il patch management garantisce che OS, applicazioni e firmware siano aggiornati. Il change management definisce il processo per le modifiche e riduce i downtime indesiderati.
- Un application allow list identifica il software autorizzato e blocca tutto il resto. Un application block list blocca il software non autorizzato.
- FDE (Full Disk Encryption) cifra un intero disco. Un SED (Self-Encrypting Drive) ha i circuiti di cifratura integrati nel drive.
- Un TPM e' un chip incluso in molti desktop e laptop: supporta FDE, secure boot e remote attestation. Ha una chiave di cifratura burned in — hardware root of trust.
- Un HSM e' un dispositivo removibile o esterno per la cifratura. Genera e conserva chiavi RSA. Un microSD HSM e' un chip microSD con un dispositivo HSM installato.
- Il metodo principale per proteggere la confidenzialita' dei dati e' la cifratura combinata con strong access controls. Puoi cifrare colonne singole, database, file, dischi interi, media removibili.
- Le tecnologie DLP prevengono la perdita di dati — possono bloccare trasferimenti su USB e analizzare email in uscita.
- La data exfiltration e' il trasferimento non autorizzato di dati fuori dall'organizzazione.
Cloud Concepts#
- SaaS: applicazioni web-based come la webmail. PaaS: OS easy-to-configure con on-demand computing — il vendor gestisce le patch. IaaS: risorse hardware via cloud.
- Un MSP e' un vendor terzo che fornisce qualsiasi servizio IT. Un MSSP si focalizza sui servizi di sicurezza.
- Un CASB e' uno strumento software tra la rete dell'organizzazione e il cloud provider — monitora il traffico e applica le security policy.
- Cloud pubblico: aperto a tutti. Private: per una singola organizzazione. Community: condiviso da organizzazioni con requisiti comuni. Hybrid: combinazione di due o piu' modelli. Multi-cloud: risorse da due o piu' CSP distinti.
- Le DLP cloud applicano le security policy ai dati nel cloud.
- Un next-generation SWG fornisce servizi proxy per il traffico client→internet: filtra URL e scansiona malware.
- Considerazioni cloud: availability, resilience, cost, responsiveness, scalability, segmentation.
- On-premises: centralizzato (poche sedi) o decentralizzato (molte sedi). Off-premises: usa CSP.
- IaC: gestire e fare il provisioning di data center con codice per definire VM e reti virtuali.
- SDN: usa tecnologie di virtualizzazione per instradare il traffico al posto di router e switch hardware.
Mobile Devices#
- I dispositivi mobili includono smartphone e tablet.
- COPE: l'organizzazione possiede il device, il dipendente puo' usarlo per ragioni personali.
- BYOD: i dipendenti connettono i propri device alla rete aziendale. CYOD: lista di device accettabili — chi ne possiede uno dalla lista puo' connetterlo.
- I dispositivi mobili si connettono via cellular, Wi-Fi, Bluetooth. Tethering permette a un device di condividere la propria connessione internet. Wi-Fi Direct connette device senza router.
- Gli strumenti MDM garantiscono che i device soddisfino i requisiti minimi di sicurezza, monitorano i device, applicano le policy e bloccano l'accesso se i device non sono conformi.
- MDM: restrict application, segment/encrypt data, enforce strong authentication, screen lock, remote wipe. Containerization e' utile con il modello BYOD.
- Geolocation: GPS per identificare la posizione. Geofencing: confine virtuale geografico — abilita/disabilita accesso in base alla posizione. Geotagging: GPS aggiunge informazioni geografiche ai file.
- Third-party app store: store diverso da quello primario (App Store per Apple, Google Play per Android). Minor livello di scrutinio — rischio maggiore.
- Jailbreaking: rimuove tutte le restrizioni software su device Apple. Rooting: accesso root su Android. MDM blocca l'accesso alla rete per device jailbroken o rooted.
- Sideloading: copiare un'applicazione su Android invece di installarla dallo store.
Embedded Systems#
- Un sistema embedded e' qualsiasi device con una funzione dedicata che usa un computer per svolgerla. La sfida principale: tenerli aggiornati.
- I device IoT interagiscono con il mondo fisico, comunicano via internet, Bluetooth o altre tecnologie wireless.
- Un SCADA controlla un ICS. L'ICS e' usato in grandi impianti come centrali elettriche o impianti di trattamento acque.
- SCADA e ICS stanno tipicamente in reti isolate senza accesso a internet, spesso protetti da NIPS.
- Un SoC e' un circuito integrato che include un sistema di computing completo.
- Un RTOS e' un OS che reagisce agli input entro un tempo specifico (deterministico).
- I vincoli principali degli embedded system: computing limitations, cryptographic limitations, power limitations, ease of deployment, cost, inability to patch.
Trappole d'esame — Cap 5#
Allow list vs block list — trigger: "antivirus didn't detect it" Se il malware e' sconosciuto, il block list fallisce (non lo conosce, lo lascia passare). L'allow list blocca tutto cio' che non e' esplicitamente approvato — anche il malware sconosciuto non gira. Quando il problema e' un'app che l'AV non ha rilevato: allow list, non block list.
Integrity measurements vs block list — trigger: "master image" + "comparing" Confrontare lo stato attuale di un sistema con una master image e' un integrity measurement, non una blacklist. La blacklist blocca nomi noti. L'integrity check rileva deviazioni dalla baseline — qualcosa e' presente che non dovrebbe esserci, oppure qualcosa e' cambiato rispetto al punto di riferimento. Trigger words: "master image", "baseline", "comparing", "discostato dalla configurazione originale".
Controllo tecnico vs amministrativo — trigger: "policy gia' aggiornata" + insider threat Se la domanda dice che la policy e' gia' stata aggiornata e chiede cosa ha la BEST chance di ridurre il rischio, la risposta e' un controllo tecnico (es. configurare endpoint per bloccare USB), non un altro controllo amministrativo (training, comunicazione). Training su una policy esistente non impedisce tecnicamente il comportamento. Il controllo tecnico lo rende impossibile.
MDM vs RFID per smartphone — trigger: "smartphones" + "unique identifier" + "asset inventory" MDM assegna identificatori digitali unici ai device (smartphone e tablet) al momento dell'enrollment. Usa quell'ID per gestire il device da remoto E per semplificare l'inventario degli asset. RFID funziona su server e laptop (tag fisico applicabile), ma la domanda stessa dice che non e' un metodo affidabile per smartphone e tablet — il testo lo esclude esplicitamente. VDI = desktop virtuale (non c'entra con l'inventario). GPS tagging = aggiunge dati geografici alle foto (non c'entra con l'identificazione del device). Per mobile asset inventory: MDM, non RFID fisico.
MDM funzionalita' chiave da ricordare:
- Restrict applications (allow/block app install)
- Remote wipe (cancella il device da remoto)
- Enforce screen lock + strong authentication
- Segment and encrypt corporate data (containerization in BYOD)
- Track asset inventory via IMEI/UDID (non RFID)
- Block access per device jailbroken/rooted
Scenario Reale#
Virtualizzazione — VM escape e lateral movement#
Sei analista in un SOC. Wazuh genera un alert: processo insolito su una VM guest che ospita un web server interno. L'host hypervisor sottostante gira su un server fisico condiviso con 12 altre VM, tra cui il SIEM stesso.
Il rischio non e' solo la VM compromessa — e' che un attaccante possa sfruttare una vulnerabilita' dell'hypervisor per fare VM escape e muoversi sull'host. Da li', tutte le altre VM sono accessibili. La visibilita' sull'hypervisor e' critica quanto quella sui guest. Prima azione: isolare la VM, non spegnerla (snapshot per forensics), poi esaminare i log dell'host.
VM Sprawl in questo stesso SOC: un analista trova 47 VM nel cluster, di cui 12 non hanno un owner registrato e 3 non vengono aggiornate da 8 mesi. Quelle 3 VM sono superficie di attacco non monitorata. Il remediation e': inventario, assegnazione owner, policy di decommissioning automatico.
Hardening endpoint — chain of trust violata#
Un alert EDR segnala che un laptop ha caricato un bootloader non firmato. Secure Boot era disabilitato manualmente. Wazuh rileva la modifica al TPM PCR (Platform Configuration Register) — il valore e' cambiato rispetto alla baseline.
Scenario reale: un dipendente ha installato un dual boot con una distro Linux non supportata e ha disabilitato Secure Boot dal BIOS per farlo funzionare. L'azione corretta e' re-abilitare Secure Boot, revocare il certificato del bootloader non firmato con mokutil, e aprire un ticket change management perche' la modifica al BIOS non e' stata approvata.
Il TPM ha registrato tutto: i PCR values al boot successivo non corrispondono piu' alla baseline — indicatore chiaro di modifica non autorizzata alla catena di boot.
Protezione dati — DLP e data exfiltration#
Un alert DLP viene generato: un file Excel con 3.400 righe e pattern che corrispondono a numeri di carta di credito (regex \d{4}[\s-]?\d{4}[\s-]?\d{4}[\s-]?\d{4}) e' stato allegato a un'email in uscita verso un dominio Gmail personale.
Il DLP intercetta l'email prima che esca dal gateway. L'analista esamina: il mittente e' un dipendente in preavviso di dimissioni da 2 settimane. Il file contiene i dati dei clienti — PCI DSS violation potenziale. Azioni: blocco immediato, notifica legal, preservazione delle prove (email, log DLP, accessi al file negli ultimi 30 giorni).
Stesso scenario senza DLP: il file esce, non sai nulla finche' i clienti non segnalano frodi sulle carte.
Cloud — CASB e shadow IT#
Wazuh + CASB integration: alert su trasferimento di 2.3 GB da un bucket S3 aziendale verso Dropbox personale di un utente autenticato. Il CASB opera inline tra la rete aziendale e il cloud provider, intercetta la richiesta e la blocca.
L'analisi mostra che l'utente ha utilizzato le proprie credenziali AWS per copiare i dati — le credenziali erano corrette, ma la policy CASB vieta il trasferimento verso storage personale. Il shared responsibility model in questo scenario: AWS garantisce che il bucket e' accessibile solo a chi ha le credenziali (loro responsabilita') — ma la policy che impedisce l'exfiltration e' responsabilita' del cliente, implementata tramite CASB.
Shadow IT nella stessa azienda: 40 dipendenti usano un'app SaaS non approvata per condividere documenti interni. Il CASB rileva il traffico verso il dominio non in whitelist e genera un report. Senza CASB, l'azienda non sa che quei documenti stanno su server di un vendor che non ha firmato il DPA (Data Processing Agreement).
Mobile — BYOD jailbroken e MDM enforcement#
Alert MDM: un device BYOD si connette alla VPN aziendale con un iPhone jailbroken. Il MDM rileva il jailbreak dalla presenza di Cydia e da system calls anomale. Policy: device jailbroken = accesso bloccato automaticamente, zero trust.
L'utente protesta: "e' il mio telefono". La risposta legale e operativa: il BYOD agreement firmato all'onboarding specifica che il device deve soddisfare i requisiti di sicurezza aziendali per accedere alle risorse corporate. Jailbreak = requisiti non soddisfatti = accesso revocato. Il device personale rimane suo, ma non accede piu' alla rete aziendale.
Scenario COPE nella stessa azienda: l'azienda possiede il device, puo' fare remote wipe in qualsiasi momento, incluso quando il dipendente lascia l'azienda. Vantaggio operativo: nessuna negoziazione legale sull'ownership dei dati.
ICS/SCADA — traffico anomalo verso VLAN isolata#
NIPS alert: pacchetti TCP sulla porta 502 (Modbus) rilevati su un segmento di rete che non dovrebbe avere connettivita' con la VLAN SCADA. Qualcuno (o qualcosa) sta cercando di comunicare con i PLC dell'impianto idrico.
Azioni immediate: isolare il segmento, escalare a OT security team, non modificare i sistemi SCADA senza approvazione OT (disponibilita' prima di tutto — uno stop non autorizzato puo' essere piu' pericoloso dell'attacco stesso). Preservare i log di rete per forensics.
Contesto: il Colonial Pipeline 2021 e' partito da credenziali VPN compromesse — non dall'OT direttamente. Ma l'impatto sull'OT (pipeline ferma per 6 giorni) e' stato reale. Stuxnet ha usato USB e vulnerabilita' Windows per raggiungere i PLC Siemens attraverso una rete fisicamente isolata. L'air-gap da solo non basta se ci sono vettori fisici (USB, laptop di manutenzione).
Lab — Cap 5#
- lab-iac-terraform-docker — IaC con Terraform e Docker
- lab-vtpm-secure-boot-uefi — vTPM e Secure Boot su UTM
- lab-dlp-python-wazuh — DLP con Python e Wazuh
Risorse#
- Gibson, CompTIA Security+ Get Certified Get Ahead SY0-701 — Cap 5
- Professor Messer, SY0-701 Video Course — https://www.professormesser.com/
Collegato a#
- cap-04-securing-your-network — capitolo precedente
- cap-06 — capitolo successivo
- cloud-security — elasticity, scalability, cloud deployment models
- indice-gibson-messer-burning-Ice — indice completo del libro